基于内容的推荐系统
基于内容的推荐系统核心思想是根据每部电影的内容以及用户已经评过分的电影来推断每个用户对每部电影的喜好程度,从而预测每个用户对没有看过电影的评分。
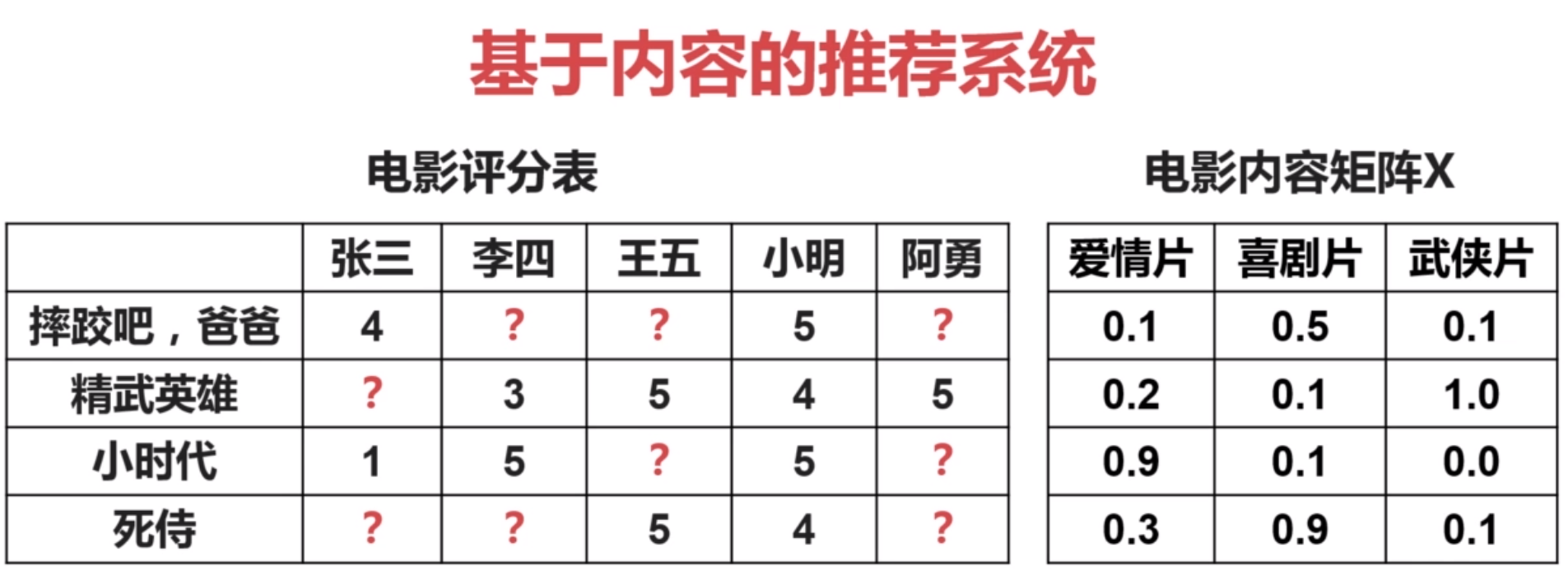
问题定义
假设已经有了电影评分表和电影内容矩阵,需要根据这两个矩阵得到用户喜好矩阵。
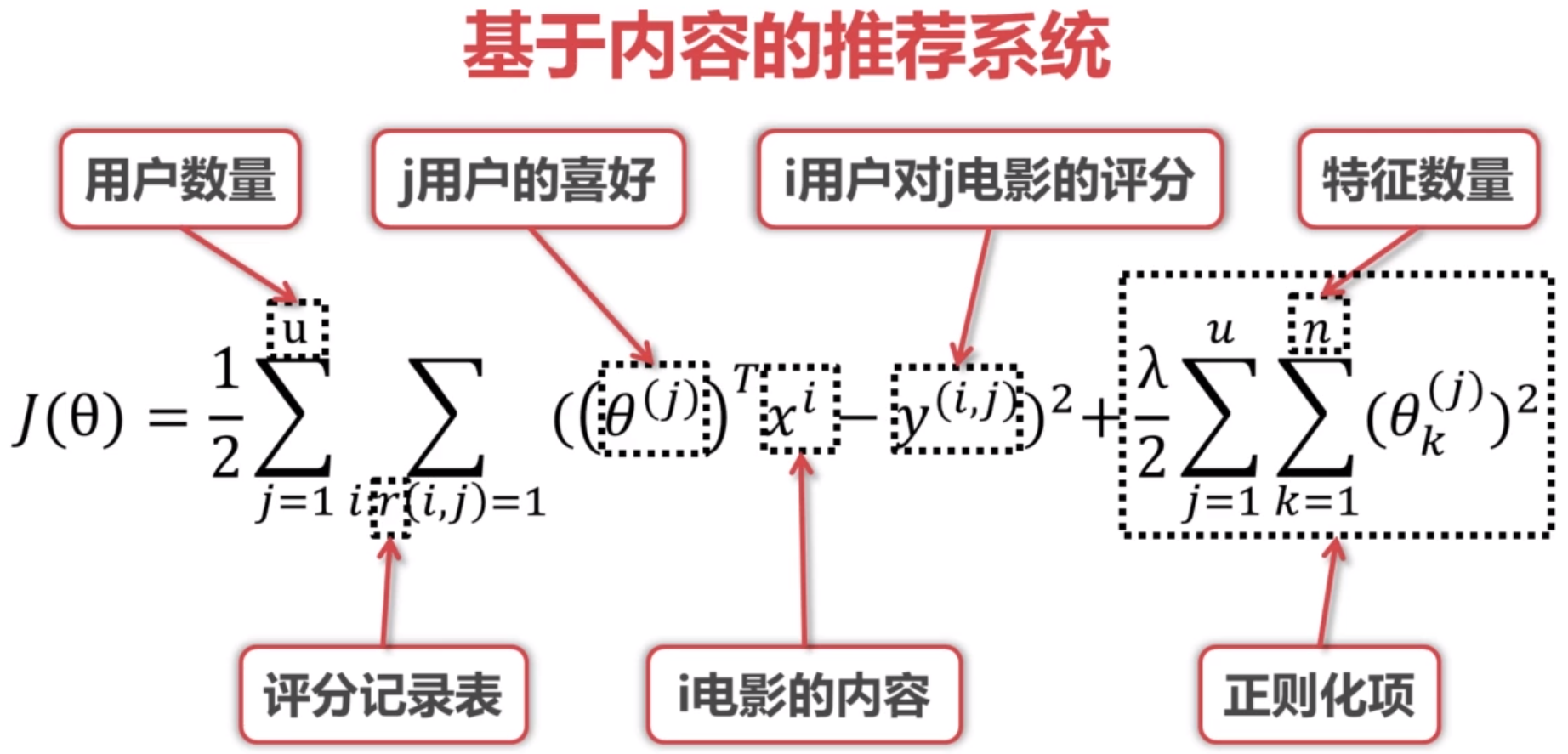
损失函数
目标是根据已经有的用户评分记录去训练一个模型,能够最小化下面的损失函数:
缺点
- 需要透彻的内容分析,电影的内容成分不好直接计算,需要人工标注,非常耗时
- 很少能给用户带来惊喜
- 存在用户冷启动的问题
优点
- 不存在商品冷启动问题
- 可以明确告诉用户推荐的商品包含哪些属性
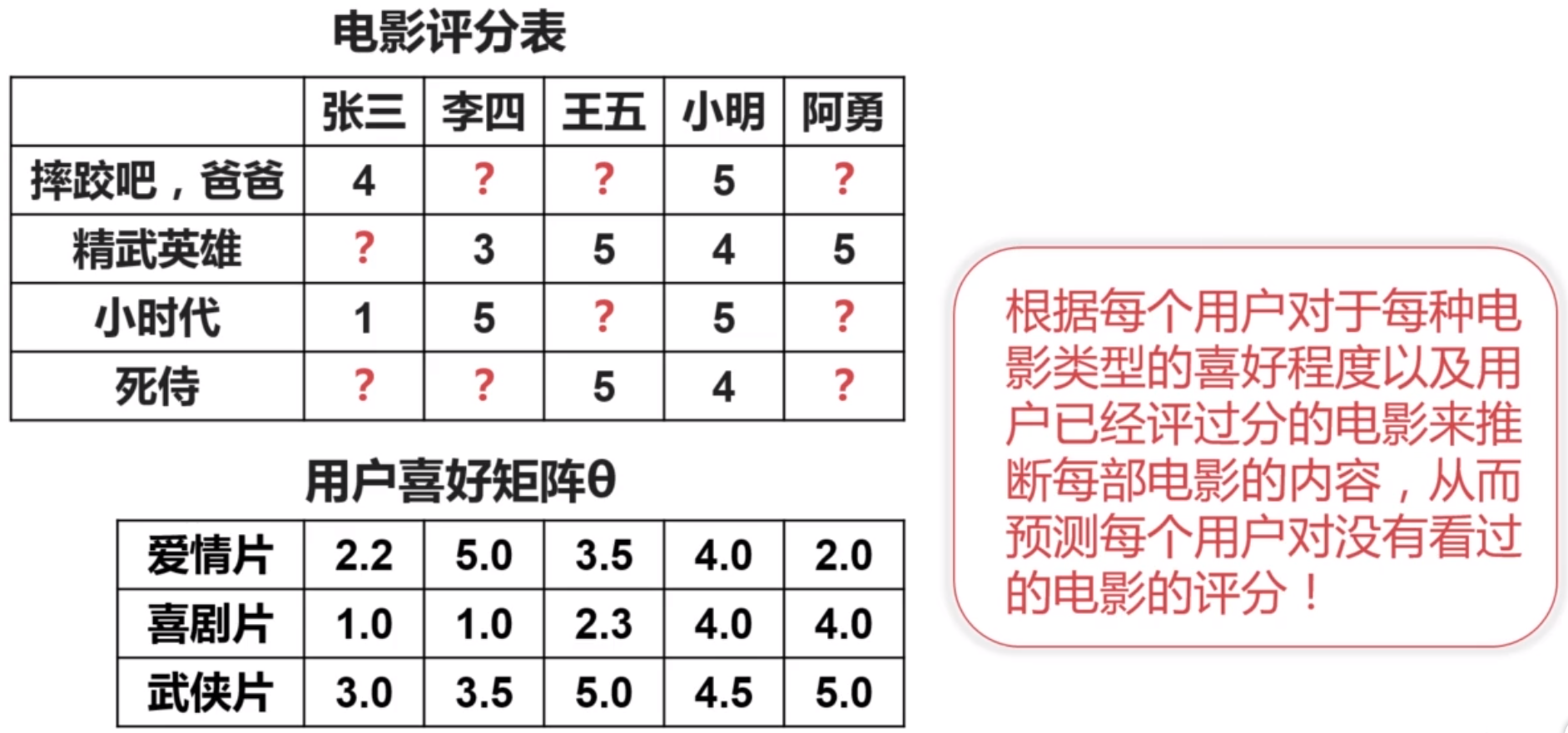
基于矩阵分解的协同过滤
基于协同过滤的推荐系统核心思想是根据每个用户对于每种电影类型的喜好程度以及用户已经评过分的电影来推断每部电影的内容,从而预测每个用户对没有看过电影的评分。
损失函数
$$ J(x,\theta) = \frac{1}{2} \sum_{(i,j):r(i,j)=1} (\theta^{(j)^T} x^{(i)} - y^{(i,j)})^2 + \frac{\lambda}{2}\sum_{i=1}^{m}\sum_{k=1}^{n}(x_k^{(i)})^2 + \frac{\lambda}{2}\sum_{j=1}^{u}\sum_{k=1}^{n}(\theta_k^{(j)})^2 $$
随机初始化电影内容矩阵X和用户喜好矩阵theta,通过梯度下降算法或者其他优化算法最小化该损失函数。使用该方法的好处在于只要有用户对电影的评分即可。
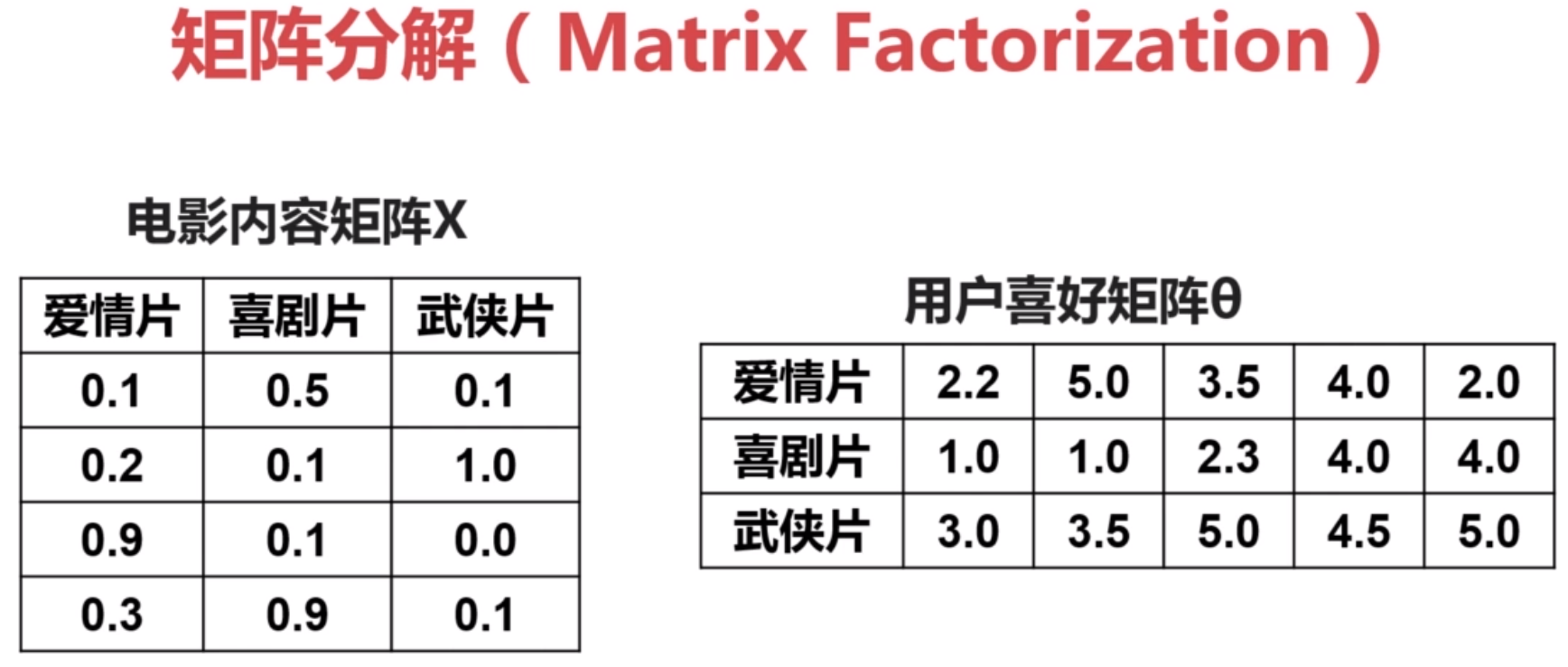
矩阵分解
上面实现协同过滤的方法实际上在做矩阵分解
优点
- 能够根据各个用户的历史信息推断出商品的质量
- 不需要对商品有任何专业领域的知识
缺点
- 冷启动问题
- gray sheep:没有相似的用户
- 协同过滤的复杂度会随着商品数量和用户数量的增加而增加
- 同义词会降低协同过滤系统的性能
- shilling attack:水军攻击
冷启动问题(Cold Start)
用户冷启动
解决方法:
- 推荐热门产品
- 补充资料,感兴趣的话题
商品冷启动
解决方法:
- 新上电影栏
- Bandit算法
混合算法
- Mixed: 将多个推荐系统的结果同时推荐给用户
- Feature Combination:将多个推荐使用的特征组合起来给另一个推荐系统
- Cascade: 将一个推荐系统的结果用另一个推荐系统进行筛选
- Switching:根据当前的状态在不同的推荐系统之间切换
推荐系统性能评估
线下评估
- RMSE
- MAE
- Recall
带有评分的记录数据数量非常少的时候,不适用上面的评估指标,但是可以利用隐式行为如看过某个商品后收藏、购买与否的布尔值来作为训练集数据,使用Recall召回率来评估推荐系统的性能好坏。Recall值越大,说明推荐系统推荐了越多用户感兴趣的商品,下图表示召回率为6/10,从图中可以看出,如果提高推荐数量,肯定可以增大命中用户感兴趣的物品数量,从而增大召回率,但是这样显然是不可取的。
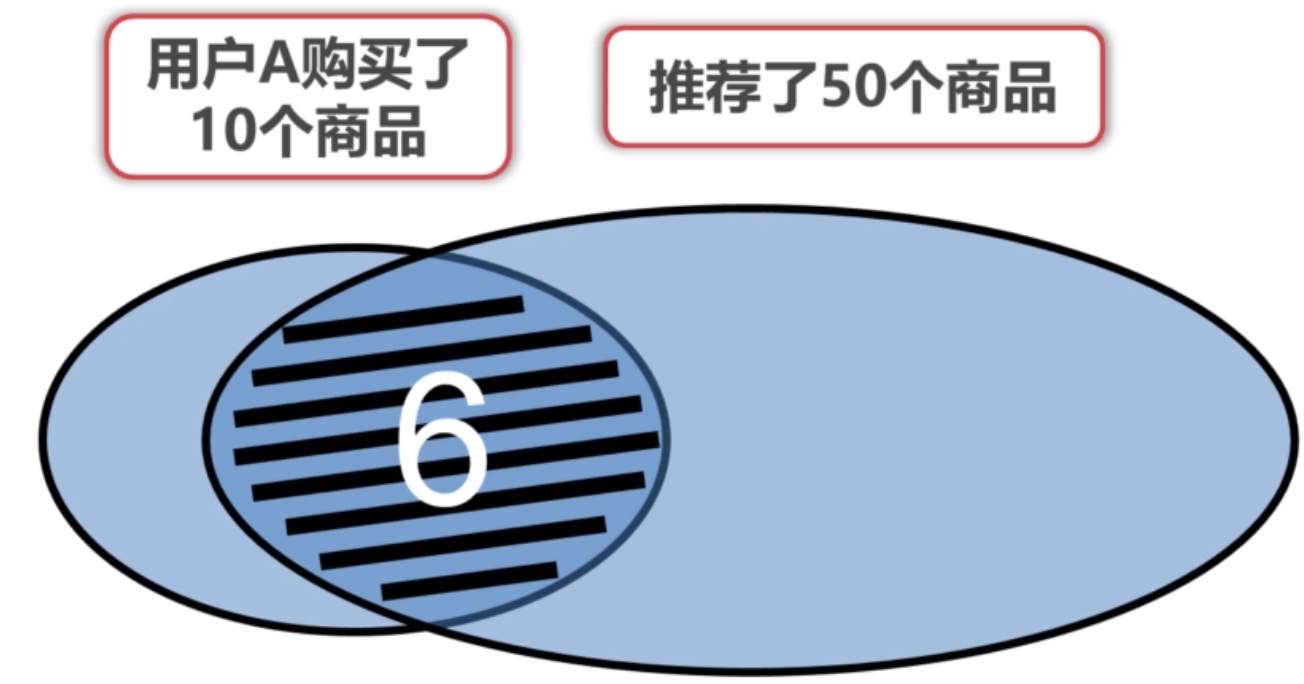
- Precision 我们希望命中的物品占推送的比例越高越好,因此可以使用Precision来衡量,下面示意图的精确率为6/50。 $$ precision = \frac{tp}{tp + fp} $$ 上面公式代表了有用商品数量与推荐商品数量交集除以推荐商品数量
- F1 Score:结合了Recall和Precision $$ F = 2 \times \frac{precision \times recall}{precision + recall } $$ F值越大说明推荐系统性能越好
线上评估
使用ABTest进行在线评估,实时测试不仅仅是AB两个测试组,而是可以多个测试组同时进行,示意图如下。

主要评估指标:
- CTR: Click Through Rate,推荐了10个商品,用户点击了3次,CTR为0.3,CTR越高,说明用户越该商品感兴趣
- CR: Conversion Rate,用户点击链接后,看完了电影,购买了商品等,不仅点击了链接,还体验了商品,这就是转化率,越高越好
- ROI:指(投资回报-投资成本)/ 投资成本,用于度量不同的投资带来的回报,计算结果是百分比,越大越好
- QA:根据个人的经验来判断推荐系统的好坏
Code: Github
Note: Cover Picture