推荐系统的测试方法
推荐系统的测试方法有:
- 业务规则扫描
- 离线模拟测试
- 在线对比测试
- 用户访谈
业务规则扫描
业务规则扫描本质上就是传统软件的功能测试。通常这些业务规则有软的和硬的两种:
- 软的:对业务规则违反情况做一个基线规定,比如触发几率小于万分之一,在扫描测试时统计触发次数,只要统计触发几率不超过基线,就算是合格
- 硬的:就是一票否决,某些业务黑名单,不能触碰
除了业务规则,其他的如数学计算也要扫描测试。
离线模拟测试
离线模拟测试通常做法是先收集业务数据,即根据业务场景特点,构造用户访问推荐接口的参数。离线模拟测试是失真的测试,并且评测指标也有限,因为并不能得到用户真实及时的反应,但是仍然有参考意义。
这些模拟得到的日志可以统称为曝光日志,可以评测一些非效果类指标。
也可以利用历史真实日志构造用户访问参数,得到带评测接口的结果日志后,结合对应的真实反馈,可以定性评测效果对比。
通常来说TopK准确率高,或者AUC高于0.5越多,对应的商业指标就会越好,这是一个基本假设。通过离线模拟评测每一天的模型效果指标,同时计算当天真实的商业指标,可以绘制出两者之间的散点图,从而回归出一个简单的模型,用离线模型效果预估上线后真实商业指标。
在线对比测试
ABTest,即在线对比测试,分流量做真实的评测,需要一个支持流量正交切分的ABTest框架。ABTest在样本充分的前提下,基本上可以定性新的推荐系统是否比老的推荐系统更加优秀。
用户访谈
前面三种方法背后思想是数据驱动,与用户做最直接的交流,对用户访谈,更重要的意义不是评测推荐系统,而是评测推荐系统的指标,设计是否合理,是否其高低反映了你预先的设定。
常用指标
实际上所有指标就是在回答两个问题:系统有多好,还能好多久。
系统有多好
检测系统有多好,分为两类:
- 深度类:就是看推荐系统在它的本职工作上做的如何,就是预测用户和物品之间的连接,预测的方法又分为评分预测和行为预测
- 广度类:就是看推荐系统的结果是否单一,多样化
深度类
针对离线模型的指标:
- 评分准确度:通常是均方根误差RMSE,或者其他误差内指标,反映预测评分效果的好坏
- 排序:推荐系统评价排序通常采用AUC,搜索引擎评价搜索结果和查询相关性,具有很强的客观属性,可以他人代替评价,但是推荐系统的结果只能用户本人评价,因此很少直接用搜索的评价指标如MAP、MRR、NDCG
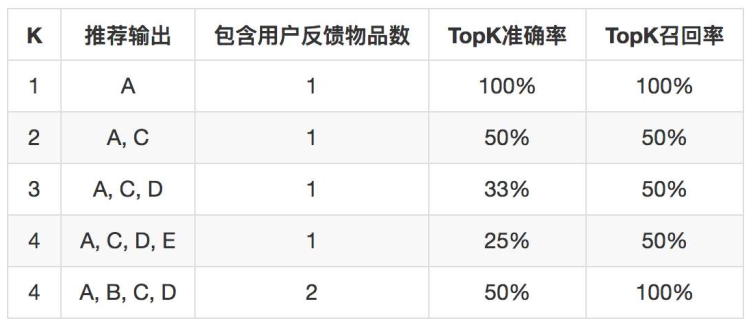
- 分类准确率:用来评价行为预测的分类准确程度,在推荐系统中一般评价TopK准确率,与之对应的还有TopK召回率,K是实际每次推荐系统需要输出的K个结果,假设用户有A、B两个物品有正反馈行为,推荐系统推出一个物品列表,长度为K,TopK计算方法如下:
典型数据采集架构
除了比例类的商业指标,还要关注绝对量的商业指标,常见的有:社交关系数量,用户停留时长,GMV(成交金额),除了因为它才是真正的商业目标外,还要看推荐系统是否和别的系统之间存在零和博弈的情况。
广度类
覆盖率
看推荐系统在多少用户身上开采成功了,细分为UV覆盖了和PV覆盖率。
UV覆盖率公式:
$$ {COV}_{uv} = \frac{N_{l > c}}{N_{uv}} $$
有效推荐指推荐结果列表长度保证在C个之上,独立访问的用户去重就是UV,有效推荐覆盖的独立去重用户数除以独立用户数就是UV覆盖率。
PV覆盖率计算方法类似,唯一区别是计算是分子分母不去重:
$$ {COV}_{pv} = \frac{N_{l > c}^*}{ N_{pv}^*} $$
失效率
失效率指标衡量推荐不出结果的情况,也分为UV失效率和PV失效率,UV失效率计算方法:
$$ {LOST}_{uv} = \frac{N_{l = 0}}{N_{uv}} $$
分子是推荐结果列表长度为0覆盖的独立用户数,分母是去重后的独立访问用户数。
PV失效率和UV失效率一样,区别是不去重,计算方法:
$$ {LOST}_{pv} = \frac{N_{l = 0}^*}{ N_{pv}^*} $$
新颖性
推荐的物品要有一定的新颖性,直观理解就是用户没有见过,需要讲粒度、物品粒度、标签粒度、主题粒度、分类粒度等等。每个粒度上评价用户没见过的物品比例。
更新率
检测推荐结果更新程度,每次推荐列表的不一样程度,新闻资讯类需要每次刷新都不一样,对更新率要求更高。一种衡量方式是每个推荐周期和上个推荐周期相比,推荐列表中不同物品的比例,这个周期可以是每次刷新,也可以是每天:
$$ UPDATE = \frac{\Delta N_{diff}}{N_{last}} $$
还能好多久
衡量推荐系统是否健康的指标通常有三个:
- 个性化:实际上真正的个性化很难,要求用每个人都独立思考、爱好明确、不受群体影响。有一个直观的方法,衡量个性化程度,取一天的日志,计算用户推荐列表的平均相似度,如果用户量较大,对用户采样
- 基尼系数:基尼系数衡量推荐系统的马太效应,反向衡量推荐的个性化程度。把物品按照累计推荐次数排序,排在位置i的物品,其推荐次数占总次数为wi,那么基尼系数为:
$$ G=1-\frac { 1 }{ n } \left( 2\sum _{ i=1 }^{ n-1 }{ { w }_{ i } } +1 \right) $$
如果推荐次数越不均匀,基尼系数就越趋近于1。 3. 多样性:通常要依赖维度体系选择,例如常见的是在类别维度上衡量推荐结果的多样性。方法是下面这样:
$$ Div = \frac{\sum_{i=1}^{n} - p_i \times \log{p_i}}{n \times \log(n)} $$
多样性衡量实际上在衡量各个类别在推荐时的熵,一共有n个类别,分母是各个类别最均匀,都得到一样的推荐次数情况下对应的熵。
这样计算是一个整体的评价,还可以评价每次推荐的多样性,每个用户的多样性。
道高一尺魔高一丈:推荐系统的攻防
攻击
攻击方要扶持一个物品,就想要推荐算法在计算他的评分时给出高分,想要打压一个物品,就要反之行事。
协同过滤的核心是群体智慧,攻击协同过滤,核心问题在于如何操控选民,选民有两种,一种是用户,一种是物品,前者是基于用户的协同过滤需要的,否则是基于物品的协同过滤需要的。
针对基于用户的协同过滤算法的攻击,目的是要让自己扶持的物品在推荐算法决定是否要推荐给一个用户时,得到高分。通常手段是,批量造价用户资料,并装作是与欺骗用户兴趣相投的人。则叫做托攻击或者Shilling Attacks,托就是水军。具体方式:
- 攻击者注册一批用户,这部分用户就是攻击者可以操纵的选民
- 让这批用户去做出和被欺骗用户一样的历史评分行为,即被欺骗用户打高分的物品,这批水军也打高分
- 这样一来,在计算用户相似度时,这一批新注册的用户都和那个被欺骗用户有较高的相似度,从而就变成了参与推荐算法是计算的选民,也就可以给扶持的物品打高分或者给打压的物品打低分
- 攻击者操纵的选民除了要做出和被欺骗用户一样的行为外,还要做出掩人耳目的行为,防止被平台发现,所以还会给一些无关的物品打分
通常被欺骗用户不是一个,而是一个目标用户群体。
攻击手段需要三个要素:
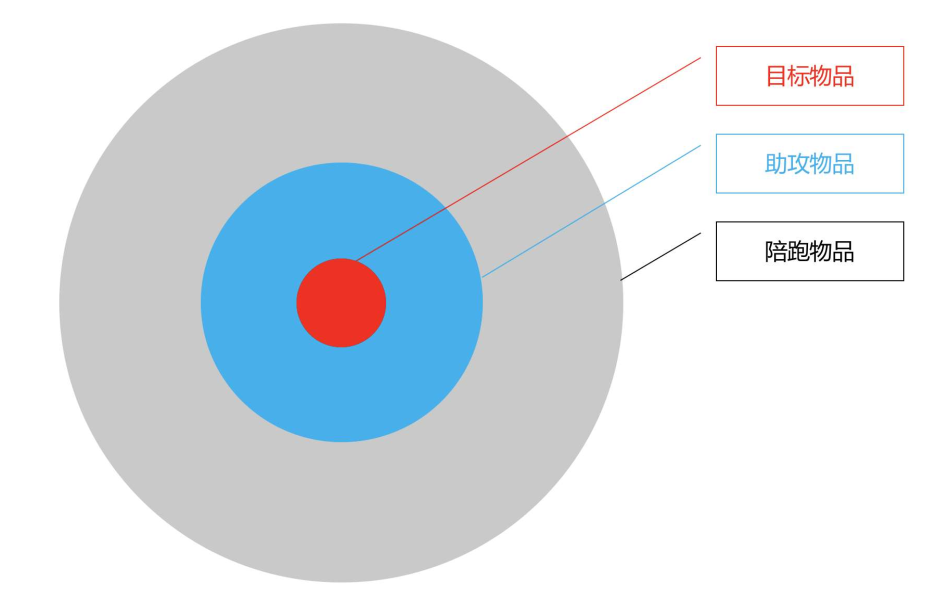
- 目标物品:就是攻击方要扶持或者打压的那个物品
- 助攻物品:就是用来构造假的相似用户所需要的物品
- 陪跑物品:就是用来掩饰造假的物品
三类物品构成一个靶子,靶心就是攻击者要拿下的,层层包围,示意图如下:
典型数据采集架构
根据对最外环物品的评分构造方法不同,可以把攻击分为两种:
- 随机攻击:随机对最外环陪跑的物品评分。随机打分就是用全局平均分构造一个正态分布,给无关物品打分时,用这个正态分布产生一个随机分值
- 平均分攻击:给最外环物品打每个物品的平均分
热门攻击就是攻击者想办法让目标物品和热门物品扯上关系,说白了就是“绑大腿”,最常用方法及时使用假用户同时给热门物品和目标物品评上高分,这是针对扶持目标物品的做法,如果要打压,则给热门物品打高分,给目标物品打低分,陪跑物品就采用随机评分的方式。
热门攻击更多的时候是一种群体现象,如粉丝出征,消费者集体维权,都可能产生出热门攻击的效果。
分段攻击就是想办法把目标物品引入到某个群体中,做法就是攻击者先全定好用户群体,再列出这个群体肯定喜欢的物品集合,然后同时假用户给目标物品这批物品集合评分。
最后的攻击效果就是:如果扶持某个物品,那个被欺骗的用户群体就会看见该物品,反之如果打压某个物品,那么该物品就不会出现在这些被欺骗的用户群体面前。
防护
防护手段按照层级,可以分为:
- 平台级:属于推荐系统之外的手段,如提高批量注册用户的成本,弹验证码
- 数据级:从数据中识别出哪些数据是假的,哪些用户是被操纵的选民,一旦识别出来就将这些数据删除,做法通常是采用机器学习思路,如
- 有监督学习:人工标注数据集,训练分类器识别
- 无监督学习:对用户数据聚类,正常用户和非正常用户肯定不一样
- 算法级:对基于用户的协同过滤算法进行改进,有:
- 进入用户质量,限制对于低质量用户的参与计算,或者限制新用户参与计算
- 限制每个用户的投票权重,即在计算用户相似度时引入较重的平滑因子,使得用户之间的相似度不容易出现过高的值,也就是变相使得投票时参与用户更多一些,提高攻击者的成本
采用多种推荐算法最后模型融合也是一种提高推荐系统健壮性的有效做法。
基于物品的协同过滤如果被攻击,直观上就不符合人们的理解,所以容易被发现,如苹果手机和某件衣服非常相似。
本文是《推荐系统三十六式》的读书笔记,仅限个人学习,请勿用作商业用途,谢谢。
Note: Cover Picture