深度学习
在矩阵分解中,我们将用户和物品之间的大关系矩阵分解为两个小矩阵,一个代表用户背后的偏好因子,一个代表物品背后的主题因子。可以把矩阵分解看成是一个拥有隐藏层的神经网络,得到的隐因子向量就是神经网络的连接权重参数。
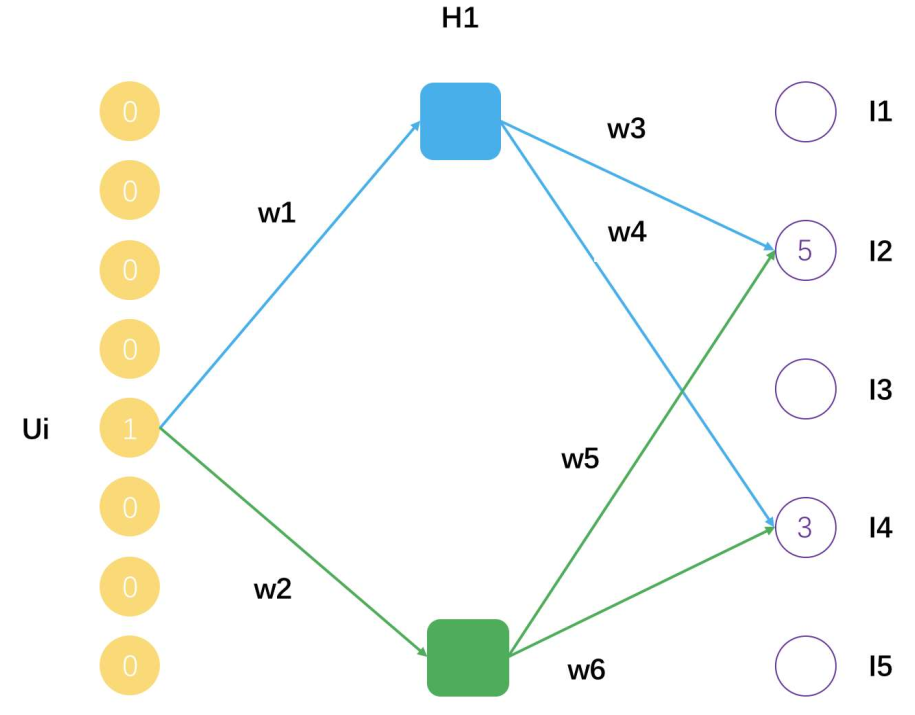
神经网络与矩阵分解的关系
这个示意图表示一个用户U_i,评分过的物品有I2和I4,分解后的矩阵隐因子数量是2,用户U_i的隐因子向量就是[w1,w2],物品I2的隐因子向量就是[w3,w5],物品I4的隐因子向量就是[w4,w6]。
深度学习的深可以看成是对本质属性的挖掘,有两个好处:
- 可以更加高效且真实地反映出事物本身的样子
- 可以更加高效真实地反映出用户和物品之间的连接
深度学习可以帮助推荐系统的地方:
- Embedding:嵌入
- 矩阵分解得到的隐因子
- Word2Vec
- Prediction:预测
- Wide & Deep
做预测的几个方向:深度神经网络的CTR预估,深度协同过滤,对时间序列的深度模型。
各种向量化
Word2Vec就是每个词都可以得到一个稠密向量,相当于矩阵分解得到的隐因子向量。训练时一个滑动窗口包含N个词,每个词用One-hot向量表示,每滑动一次,可以产生N-1条样本,可以通过两个训练方法得到词的嵌入向量:
- 每条样本都是用窗口内的一个词去预测正中间那个词
- 每条样本都是用正中间的那个词去预测其余的N-1个词
这样隐藏层的神经元个数就是最终得到嵌入向量的维数,最终得到的嵌入向量值,就是输入词的向量表示与输入层和隐藏层连接权重的乘积。
Word2Vec
在实际中,利用词预测词的目的是为了得到词的嵌入向量,Embedding本身才是目的。
Sentence2Vec
把一个句子表示成一个嵌入向量,通常是把其包含的词嵌入向量加起来就行。
Doc2Vec
- 多个句子构成一个段落,Doc其实就是段落。Doc2Vec在窗口滑动过程中构建N-1条样本时,还增加一条段落ID预测中间那个词,相当于窗口滑动一次得到N条样本
- 一个段落中有多少个滑动窗口,就得到多少条关于段落ID的样本,相当于这个段落中,段落ID在共享嵌入向量,段落ID像个特殊的词一样,也得到属于自己的嵌入向量,也就是Doc2Vec
自动编码机 AutoEncoder
是一种输入和输出一样的网络,学到的网络连接权重都是不同的嵌入向量对应的权重。从输入数据逐层降维,相当于是一个对原始数据的编码过程,到最低维度的那一层后开始逐层增加神经元,相当于是一个解码过程,解码输出要和原始数据越接近越好,相当于在大幅度压缩原始特征空间的前提下,压缩损失越小越好。
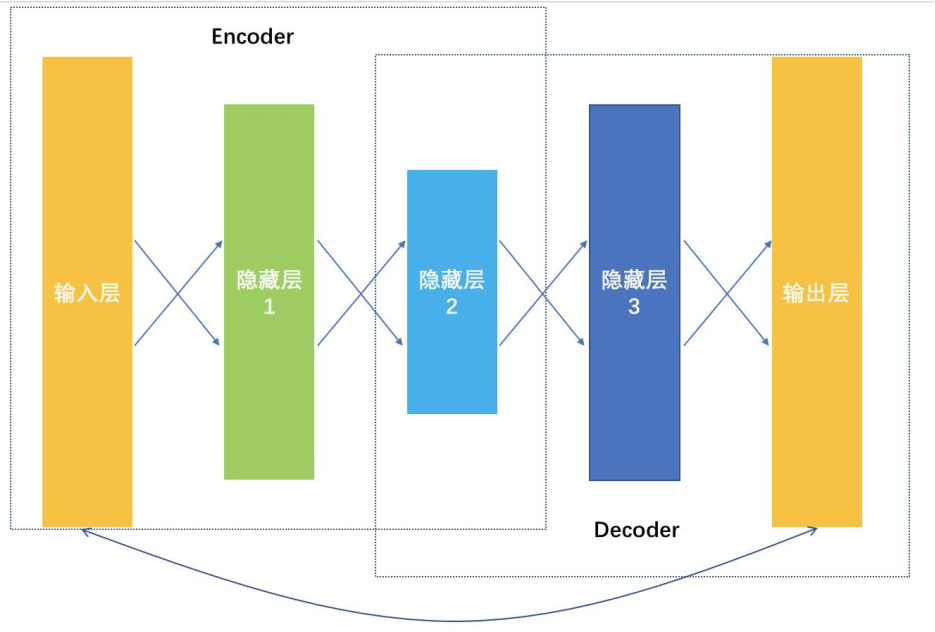
AutoEncoder结构图
推荐系统中的向量化
将用户添加到购物车中的商品、用户在APP商店中的下载序列看成文档,利用Word2Vec的思想学习到商品和应用的嵌入表示,然后可以用于做相关物品的推荐,或者作为基础特征加入到其他推荐模型中使用。
可以将嵌入向量与矩阵分解的隐因子向量结合,拼接成一个更大的稠密向量去做CTR预估。
利用RNN构建个性化音乐播单
在推荐系统领域,时间序列就是用户操作行为的先后。
普通神经网络的隐藏层参数只有输入x决定,因为当神经网络在面对一条样本时,这条样本是孤立的,不考虑其前一个样本是什么,循环神经网络的隐藏层不只是受输入x影响,还收到上一个时刻的隐藏层参数影响。
RNN的表达式:
RNN的输出不仅仅只有当前xt作用,还有t-1时刻隐藏层输出h(t-1)的作用,
数据
个性化播单的生成,不再是推荐一个一个独立的音乐,而是推荐一个序列给用户,听完上一首歌会影响下一首歌的推荐结果。将推荐问题看成是根据用户当前的回话信息,如听的歌曲,评论记录等作为输入,输出的是歌曲库中m首歌的分类概率,用Softmax作为输出层函数。输入是一个待推荐m首歌曲的one-hot向量和t-1时刻隐藏层的输出h(t-1),示意图如下:
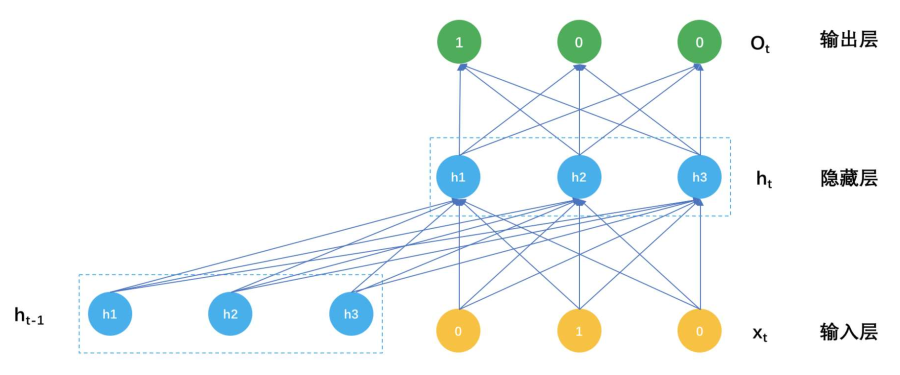
一个播单生成模型的参数就是这个三大块:
- 连接输入和隐藏之间的矩阵W_{m * k}
- 连接上一个隐藏状态和当前隐藏状态的矩阵:U_{k * k}
- 连接隐藏层和输出层的矩阵V_{k * m}
通过训练,就可以得到歌单推荐模型。
逻辑回归模型参数训练过程:
- 初始化参数
- 用当前的参数预测样本的类别概率
- 用预测的概率计算交叉熵
- 用交叉熵计算参数的梯度
- 用学习步长和梯度更新参数
- 迭代上述过程直到满足设置的条件
总结
深度学习在推荐系统中的应用主要是在特征表达学习和排序模型上,各种嵌入技术得以让物品、用户、关系等对象的特征化有更好的输出。但是数据量少的情况下不建议使用深度学习。
本文是《推荐系统三十六式》的读书笔记,仅限个人学习,请勿用作商业用途,谢谢。
Note: Cover Picture