哈希算法
Hash:散列表、散列函数、哈希算法。
哈希算法:将任意和长度的二进制值串映射为固定长度的二进制值串,这个映射的规则就是哈希算法,通过原始数据映射之后得到的二进制值串就是哈希值。
优秀的哈希算法需要满足:
- 从哈希值不能反向推导出原始数据,所以哈希算法也叫单向哈希算法
- 对输入数据非常命啊,原始数据只修改1 bit,最后的哈希值也大不相同
- 散列冲突的概率要很小,对于不同的原始数据,哈希值相同的概率非常小
- 哈希算法的执行效率要尽量高效,针对较长的文本,也能快速地计算出哈希值
哈希算法的应用
安全加密
最常用于加密的哈希算法是MD5(Message-Digest Algorithm, MD5消息摘要算法)和SHA (Secure Hash Algorithm,安全散列算法)。其他的如DES(Data Encryption Standard,数据加密标准)、AES(Advanced Encryption Standard,高级加密标准)。
MD5的哈希值是128位的Bit长度,无论文本的长度多少,经过MD5哈希之后的哈希值长度都是相同的,看起来像是一堆随机数,完全没有规律。
不管什么哈希算法,只能尽量减少碰撞冲突的概率,理论上是没办法做到完全不冲突的。可以用组合数学中的一个非常基础的理论鸽巢原理,也叫抽屉原理解释。
即如果有10个鸽巢,有11只鸽子,那肯定有一个鸽巢中的鸽子数量多于1个,换句话说,肯定有2只鸽子在一个鸽巢内。
哈希算法产生的哈希值的长度是固定且有限的,即能够表示的数据是有限的,但是要哈希的数据是无穷的,所以总会有冲突存在情况,但是哈希值越长的哈希算法,散列冲突发生的概率越低。
尽管哈希算法存在散列冲突的情况,但是因为哈希值的范围很大,冲突的概率很低,在有限的时间和资源条件下,难以破解,所以在大多数情况下可以使用哈希算法。
没有绝对安全的加密,越复杂、越难破解的加密算法,需要的计算时间也越长。
唯一标识
对于海量数据的搜索,如图库中搜索一张图片,由于任何文件在计算机中都可以标识成二进制码串,因此可以借助哈希算法将文件的二进制码串转换为信息指纹或者信息摘要作为唯一标识,并且保存到散列表中,将新图片也进行哈希操作,然后在散列表中搜索唯一标识来判断图库中是否存在某张图片,这样就减少了很多的工作量。如可以对图片取前中后各100字节组合之后进行哈希作为唯一标识,即hash(file) = hash(file[:100] + file[500:600]+file[-100:])。
数据校验
对于网络下载的文件,通过校验下载的文件哈希值和提供的文件哈希值是否相等,判断下载的数据完整性和正确性。
散列函数
散列函数中用到的散列算法,更加关注散列后的值是否能平均分布,对于是否能方向解密并不关心,一般都比较简单,比较追求效率。
负载均衡
负载均衡算法有很多,如轮询、随机、加权轮询等。可以利用哈希算法实现一个会话粘滞(Session Sticky)的负载均衡算法,即在同一个客户端上,在一次会话中的所有请求都路由到同一个服务器上。
通过哈希算法,对客户端IP地址或者会话ID计算哈希值,将取得的哈希值与服务器列表的大小进行取模运算,最终得到的值就是应该被路由到的服务器编号。
数据分片
针对海量数据处理的问题,我们可以采用多级分布式处理,借助这种分片的思路,可以突破单机内存、CPU等资源的限制。
如何统计“搜索关键词”出现的次数
先对数据切片,然后采用多台机器处理的方法,来提高处理速度。先从搜索记录的日志文件中读出每个关键词,通过哈希函数计算哈希值,然后再跟n取模,n为服务器数量,得到的值就是关键词应该被分配到的机器编号。
每一台机器负责统计分配到的关键词次数,针对同一个关键词,一定在同一个服务器上,但是同一台服务器上存储的是不同的关键词。最后合并起来n台服务器的统计数据就是最终的统计结果。这也是MapReduce的基本设计思想。
如何快速判断1亿张图片是否在图库中
如果在单台机器上对1亿张图片直接构建散列表,单台机器的内存有限不能解决该问题,因此可以先对数据进行分片处理,分配到多台服务器进行处理即可,处理思路和上一个搜索类似。
分布式存储
对于海量的数据缓存,一台机器是不够的,需要将数据通过哈希函数并且取模映射到多台机器上。如果数据增多,原来的10个机器无法承受,需要扩容,不能直接扩容,对于缩容的情况,也不能直接删除服务器,这样会造成相同数据哈希值映射到不同的机器上,如从10台机器扩容到11台机器,导致原来的13倍分配到2号机器上了,示意图如下:
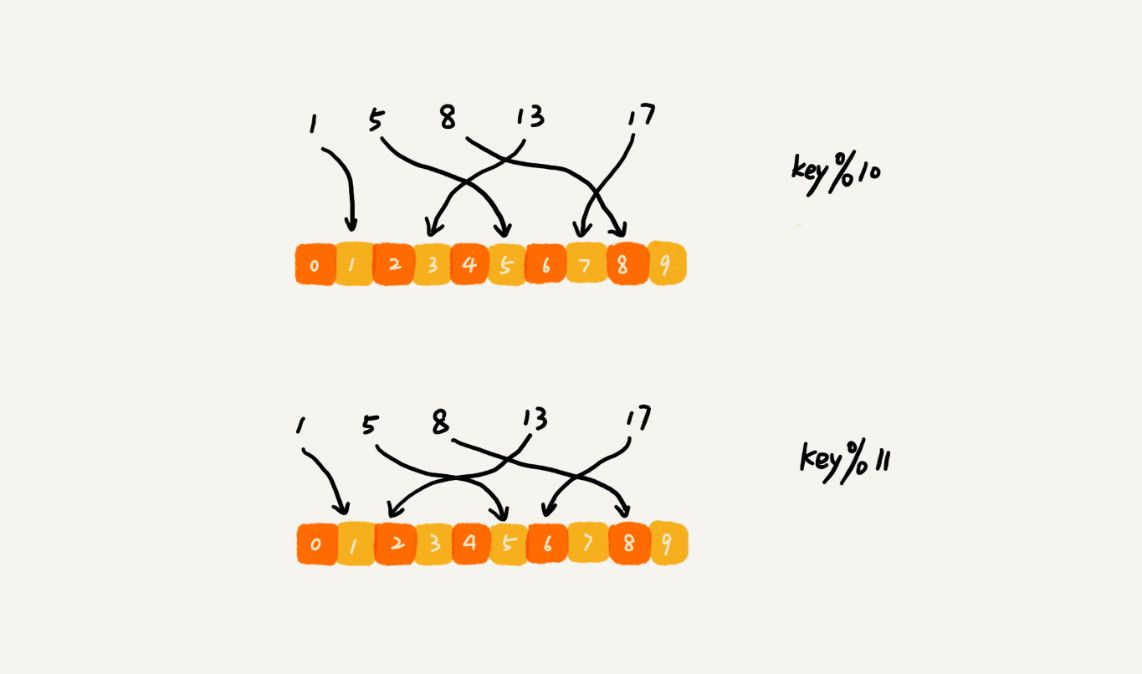
因此,在扩容或者缩容时,所有的数据都需要重新计算哈希值,然后重新搬移到正确的机器上,相当于缓存中的数据都失效了,所有的数据请求都会穿透缓存,直接去请求数据库,这样就会发生雪崩效应,压垮数据库。
解决雪崩效应的方法是在新加入一个机器后,并不需要做大量的数据搬移,即一致性哈希算法(Consistent Hashing),漫画解释。其核心思想是:假设我们有k个机器,数据的哈希值的范围是[0,max],将整个范围划分为m个小区间,m远大于k,每个机器负责m/k个小区间,当有新机器加入的时候,将某几个小区间的数据,从原来的机器中搬移到新的机器中,这样,既不用全部重新哈希、搬移数据,也保持了各个机器上数据数量的均衡。
如何防止用户数据被脱库
利用哈希算法将用户的隐私信息加密,为了防止字典攻击,引入一个盐(salt),即在信息头部、中部或者尾部添加其他随机数据,跟用户的信息组合在一起,增加密码得复杂度,然后用组合之后的字符串来做哈希加密,将它存储到数据库中,进一步增加破解的难度。
大公司都采用无论密码长度多少,计算字符串hash时间都固定或者足够慢的算法如PBKDF2WithHmacSHA1,来降低硬件计算hash速度,减少不同长度字符串计算hash所需时间不一样而泄漏字符串长度信息,进一步减少风险。
注:本文是《数据结构与算法之美》的读书笔记,配套代码地址GitHub。本文仅限个人学习,请勿用作商业用途,谢谢。
Note: Cover Picture