树
本节主要讲解树:

树的示意图如下:
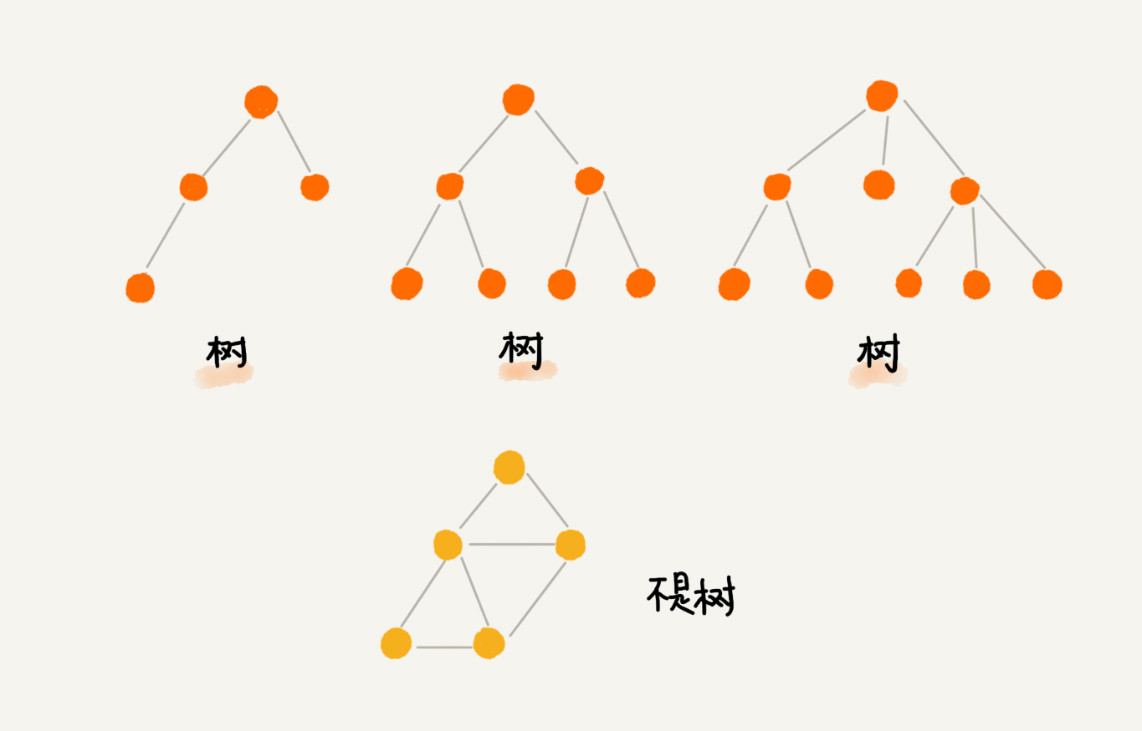
每个元素叫作”节点“,用来连接相邻节点之间的关系,叫作”父子关系“。没有父节点的节点叫作根节点,没有子节点的节点叫作叶子节点或者叶节点。
高度(Height)、深度(Depth)、层数(Level)定义如下:

示意图如下:
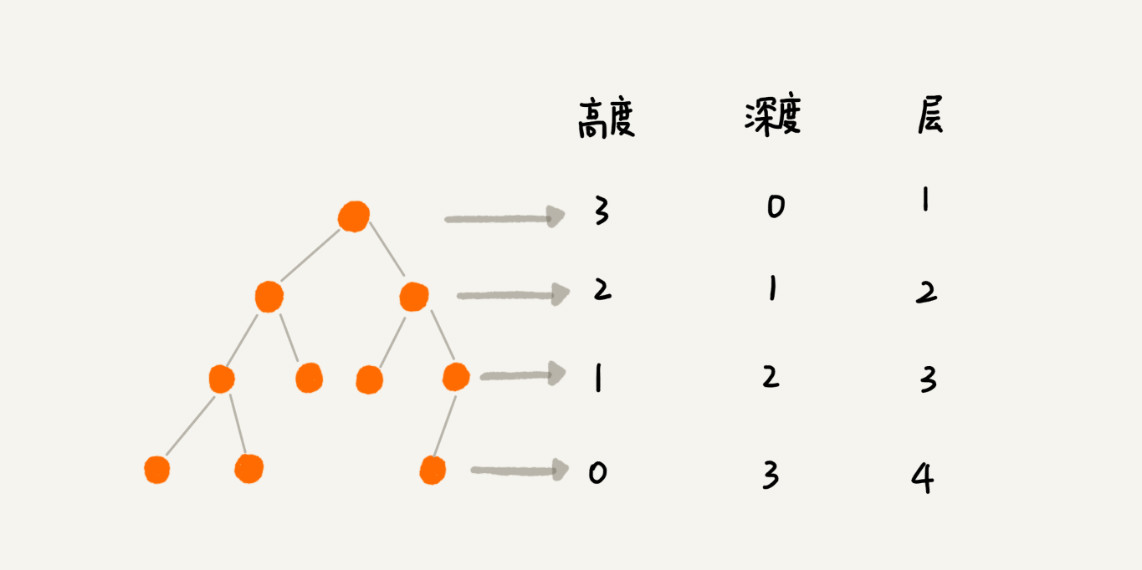
层数跟深度的计算类似,不过,计数起点是1,也就是说根节点位于第1层。
二叉树 Binary Tree
二叉树,每个节点最多有两个叉,也就是两个子节点,分别是左子节点和右子节点。每个节点并不要求必须都有两个子节点,二叉树的示意图如下:
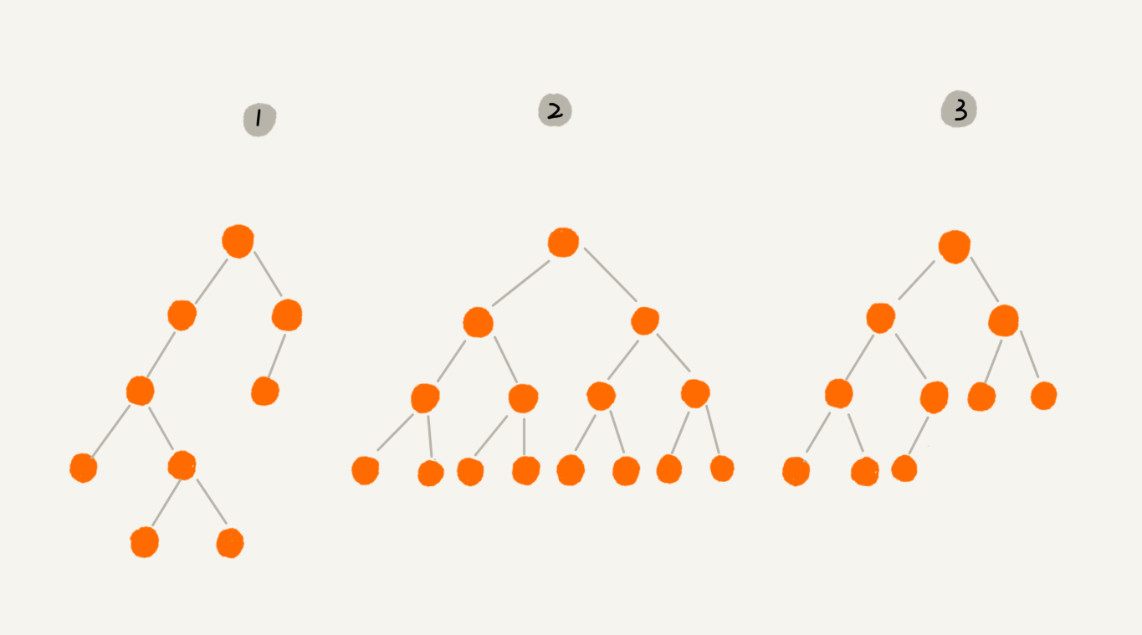
上图中编号2的叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个子节点,这种二叉树叫作满二叉树。
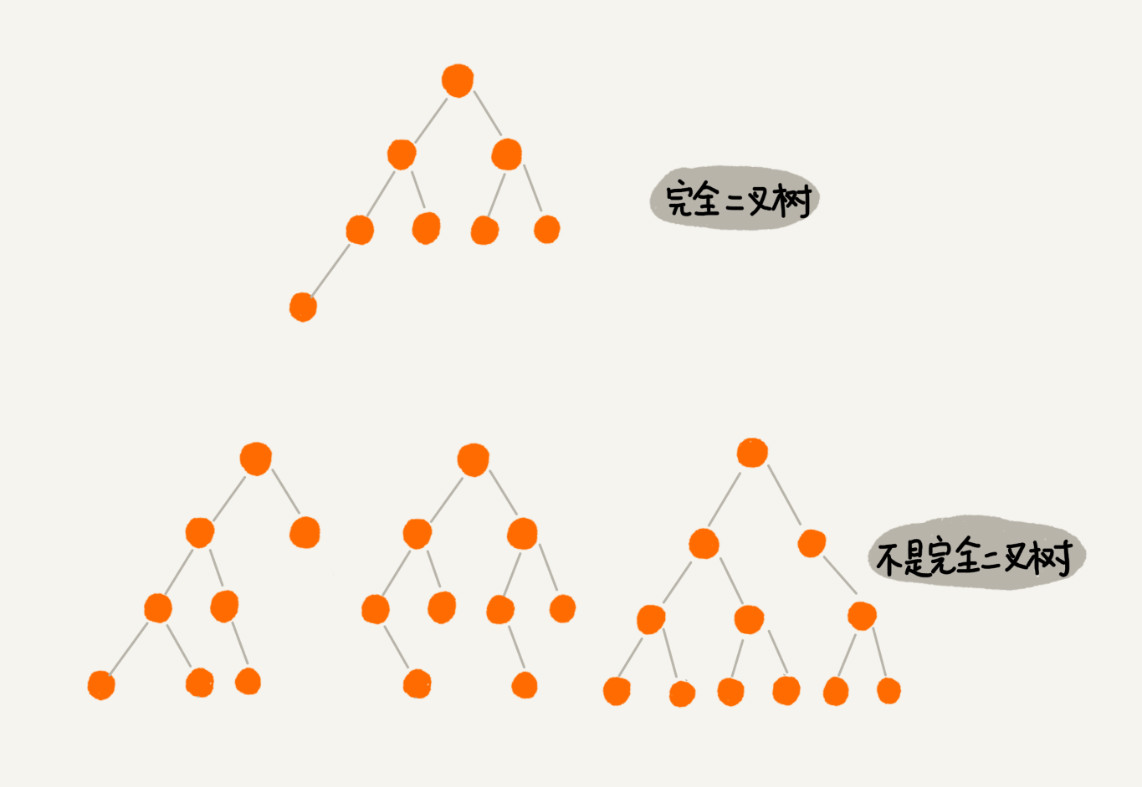
编号3的二叉树中,叶子节点都在最底下两层,最后一层的叶子节点都靠右排列,并且除了最后一层,其他层的节点个数都要达到最大,这种二叉树叫作完全二叉树。满二叉树是完全二叉树的特殊情况。
有两种方法可以存储二叉树,一种是基于指针或者应用的二叉链式存储法,一种是基于数组的顺序存储法。
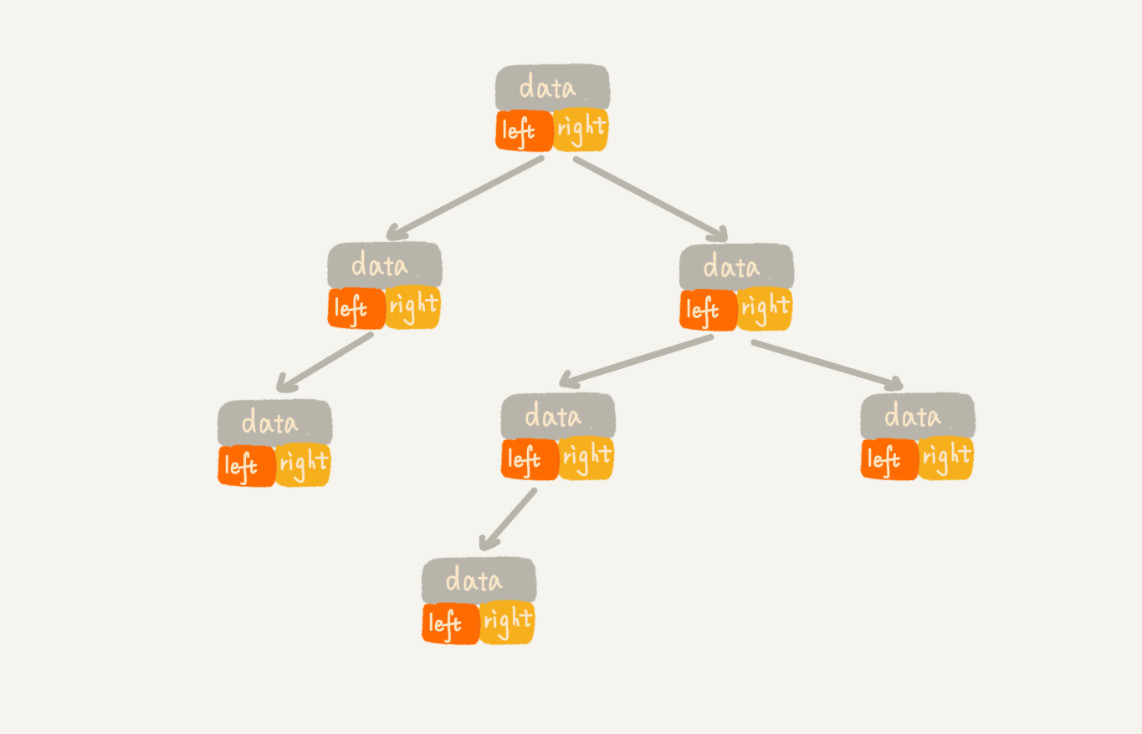
链式存储法
每个节点有三个字段,其中一个存储数据,另外两个是指向左右子节点的指针,大部分二叉树代码都是通过这种结构实现的。
顺序存储法
示意图如下:
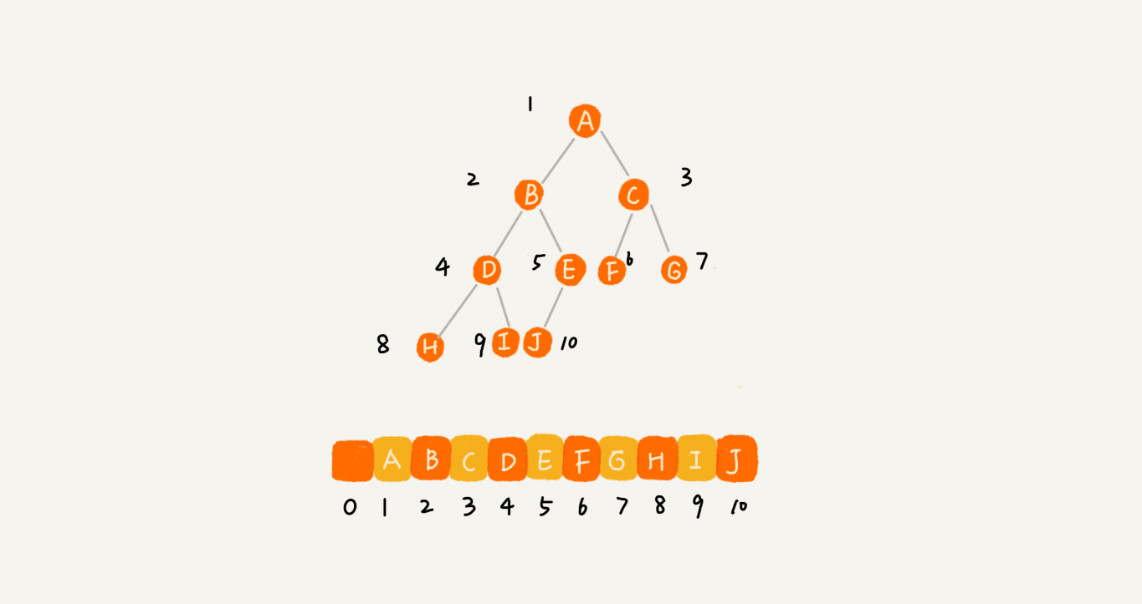
如果节点X存储在数组中下标为i的位置,下标为2*i的位置存储的就是左子节点,下标为2*i+1的位置存储的就是右子节点,反过来,下标为i/2的位置存储就是它的父节点。
通常为了方便计算子节点,根节点会存储在下标为1的位置,通过下标计算,可以把整棵树都串起来,这样会浪费位置为0的一个存储空间。
如果为完全二叉树的情况下,是浪费1个内存空间,但是,非完全二叉树会浪费更多的空间,如下:
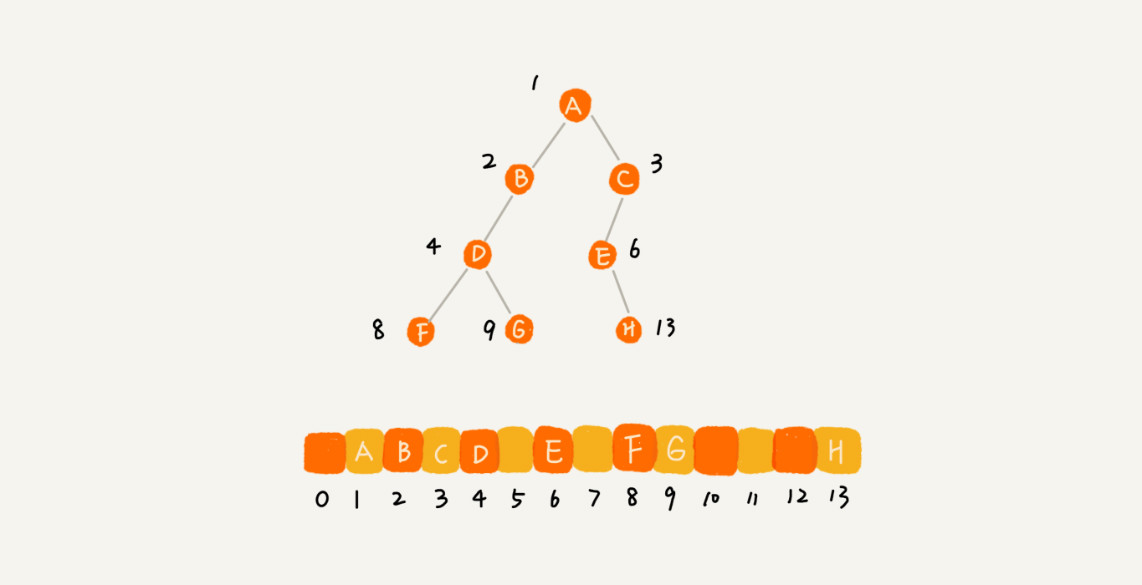
因此,完全二叉树用数组存储是最节省内存的一种方式,因为不会像链式存储一样需要存储左右两个指针,也是为什么完全二叉树要求最后一层子节点都靠左的原因。
二叉树的遍历
树的遍历有前序遍历、中序遍历和后序遍历,相对于节点与它的左右子树节点遍历打印的先后顺序,示意图如下:
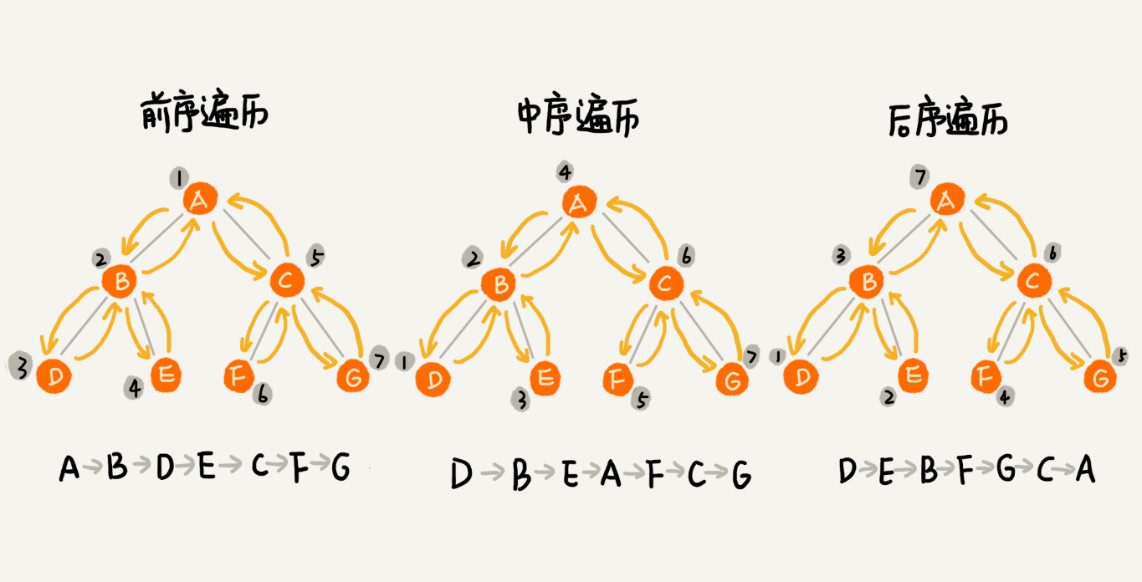
实际上,二叉树的前、中、后序遍历就是一个递归的过程。递推公式如下:
// 前序遍历的递推公式:
preOrder(r) = print r->preOrder(r->left)->preOrder(r->right)
// 中序遍历的递推公式:
inOrder(r) = inOrder(r->left)->print r->inOrder(r->right)
// 后序遍历的递推公式:
postOrder(r) = postOrder(r->left)->postOrder(r->right)->print r
对应的代码为:
void preOrder(Node* root) {
if (root == null) return;
print root // 此处为伪代码,表示打印 root 节点
preOrder(root->left);
preOrder(root->right);
}
void inOrder(Node* root) {
if (root == null) return;
inOrder(root->left);
print root // 此处为伪代码,表示打印 root 节点
inOrder(root->right);
}
void postOrder(Node* root) {
if (root == null) return;
postOrder(root->left);
postOrder(root->right);
print root // 此处为伪代码,表示打印 root 节点
}
二叉树遍历时,每个节点最多被访问2词,因此遍历的时间复杂度与节点个数成正比,其时间复杂度是O(n)。
二叉查找树 Binary Search Tree
二叉查找树,也叫做二叉搜索树,最大特点是支持动态数据集合的快速插入、删除、查找操作。其要求在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值,示意图如下:
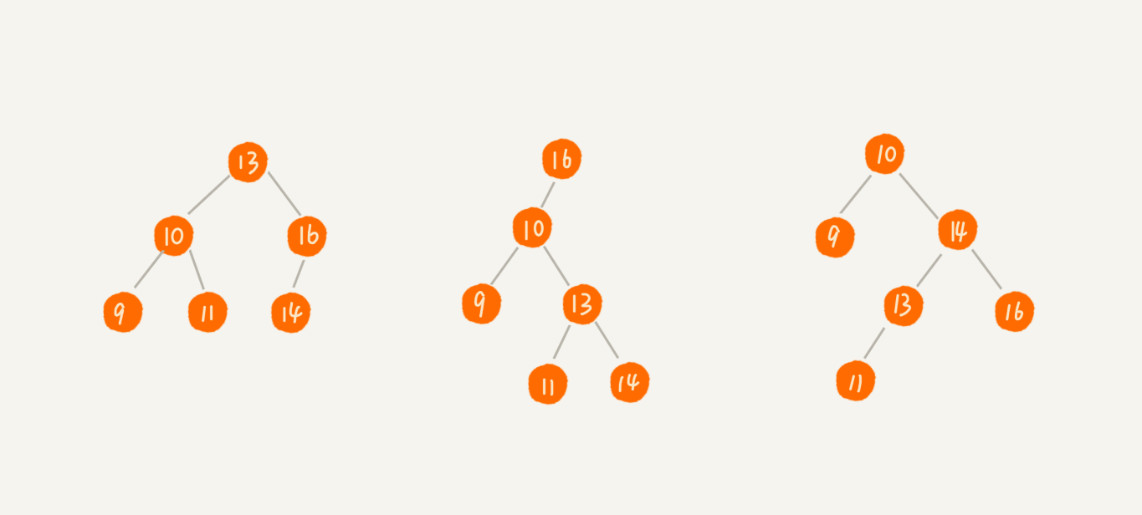
二叉查找树的查找操作
类似二分查找法,示意图如下:
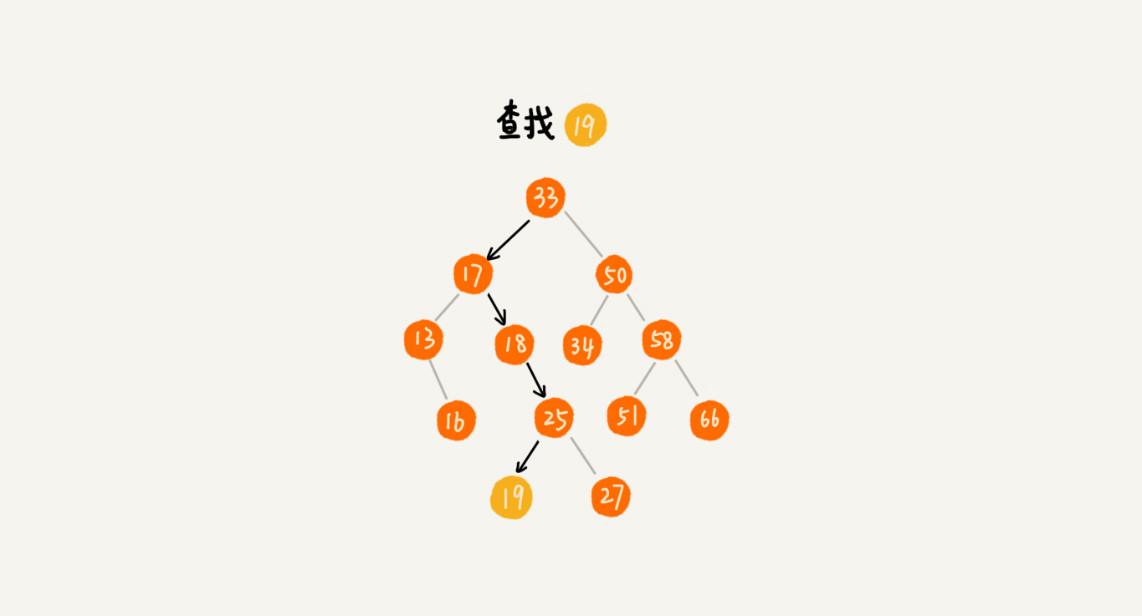
代码如下:
public class BinarySearchTree {
private Node tree;
public Node find(int data) {
Node p = tree;
while (p != null) {
if (data < p.data) p = p.left;
else if (data > p.data) p = p.right;
else return p;
}
return null;
}
public static class Node {
private int data;
private Node left;
private Node right;
public Node(int data) {
this.data = data;
}
}
}
二叉查找树的插入操作
二叉查找树的插入过程是先查找,然后判断一个节点的左右节点是否存在,然后插入即可,示意图如下:
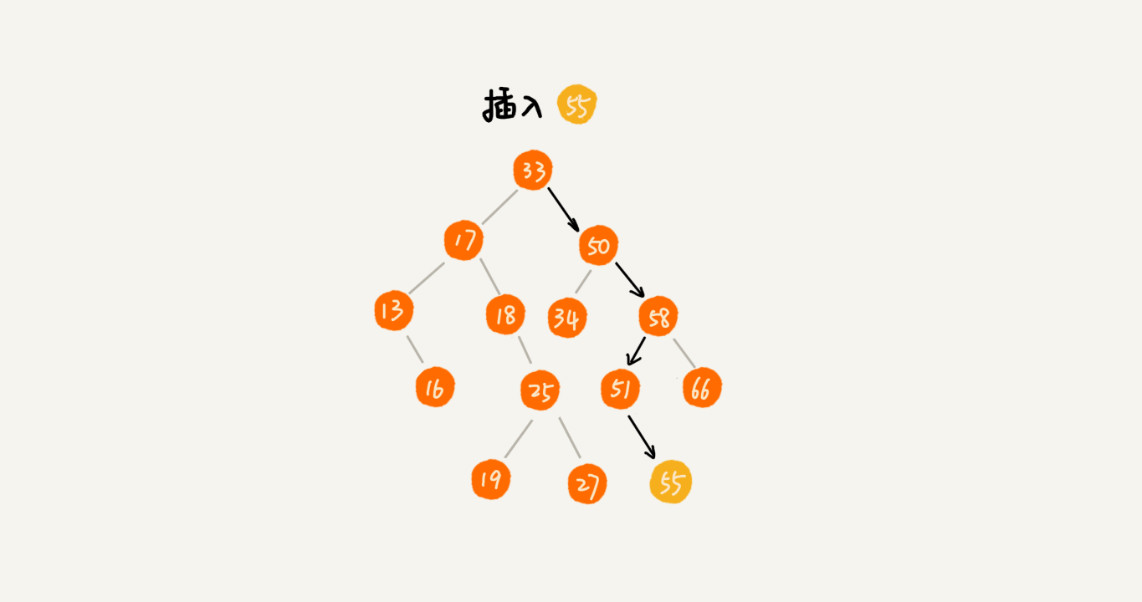
代码如下:
public void insert(int data) {
if (tree == null) {
tree = new Node(data);
return;
}
Node p = tree;
while (p != null) {
if (data > p.data) {
if (p.right == null) {
p.right = new Node(data);
return;
}
p = p.right;
} else { // data < p.data
if (p.left == null) {
p.left = new Node(data);
return;
}
p = p.left;
}
}
}
二叉查找树的删除操作
删除操作比较麻烦,需要分三种情况:
- 待删除节点无左右子节点
- 待删除节点只有一个子节点
- 待删除的节点有左右子节点
示意图如下:
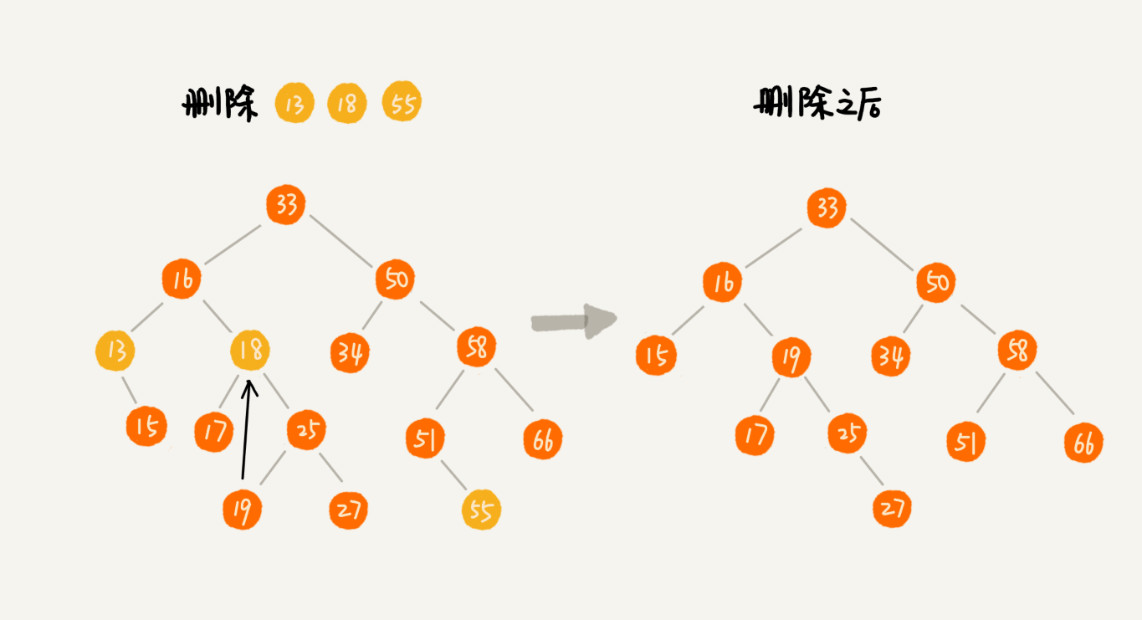
代码如下:
public void delete(int data) {
Node p = tree; // p 指向要删除的节点,初始化指向根节点
Node pp = null; // pp 记录的是 p 的父节点
while (p != null && p.data != data) {
pp = p;
if (data > p.data) p = p.right;
else p = p.left;
}
if (p == null) return; // 没有找到
// 要删除的节点有两个子节点
if (p.left != null && p.right != null) { // 查找右子树中最小节点
Node minP = p.right;
Node minPP = p; // minPP 表示 minP 的父节点
while (minP.left != null) {
minPP = minP;
minP = minP.left;
}
p.data = minP.data; // 将 minP 的数据替换到 p 中
p = minP; // 下面就变成了删除 minP 了
pp = minPP;
}
// 删除节点是叶子节点或者仅有一个子节点
Node child; // p 的子节点
if (p.left != null) child = p.left;
else if (p.right != null) child = p.right;
else child = null;
if (pp == null) tree = child; // 删除的是根节点
else if (pp.left == p) pp.left = child;
else pp.right = child;
}
中序遍历二叉查找树,可以输出有序的数据序列,时间复杂度是O(n),非常高效。因此二叉查找树又叫二叉排序树。
支持重复数据的二叉查找树
二叉查找树中可能是以某个对象的某个字段作为键值来构建的,把对象中的其他字段叫做卫星数据,因此插入数据时,二叉查找树中可能出现两个对象键值相同的情况,解决方法有两种:
- 每个节点不是只存储一个数据,而是通过链表和支持动态扩容的数组等数据结构,把键相同的数据都存储在同一个结点上。
- 每个结点只存储一个数据,在查找插入位置的过程中:
- 如果遇到相同节点值,就将要插入的数据放到这个节点的右子树,即将新插入的数据当做大于这个节点的值来处理,示意图如下:
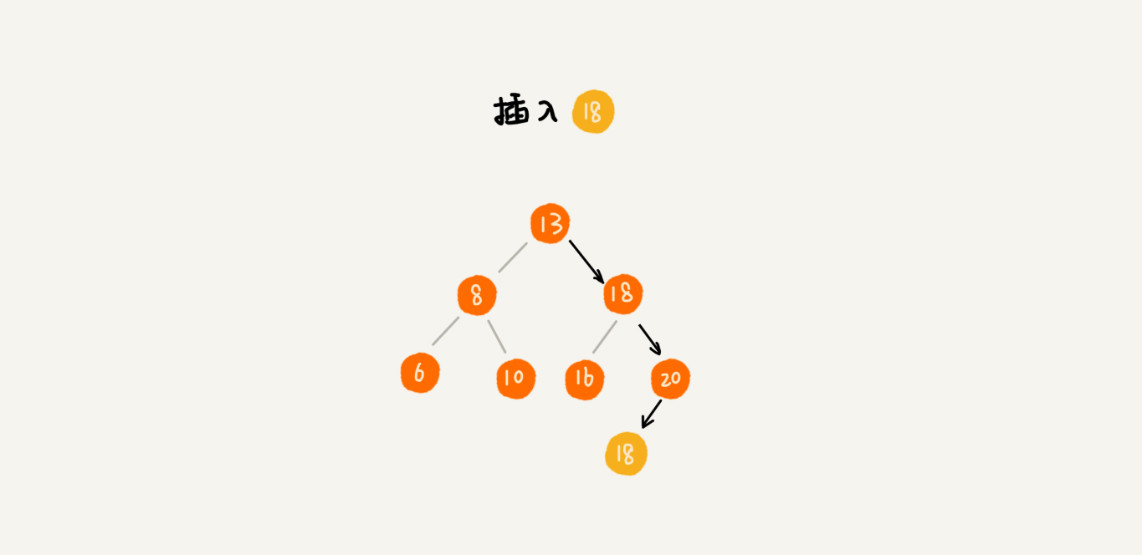
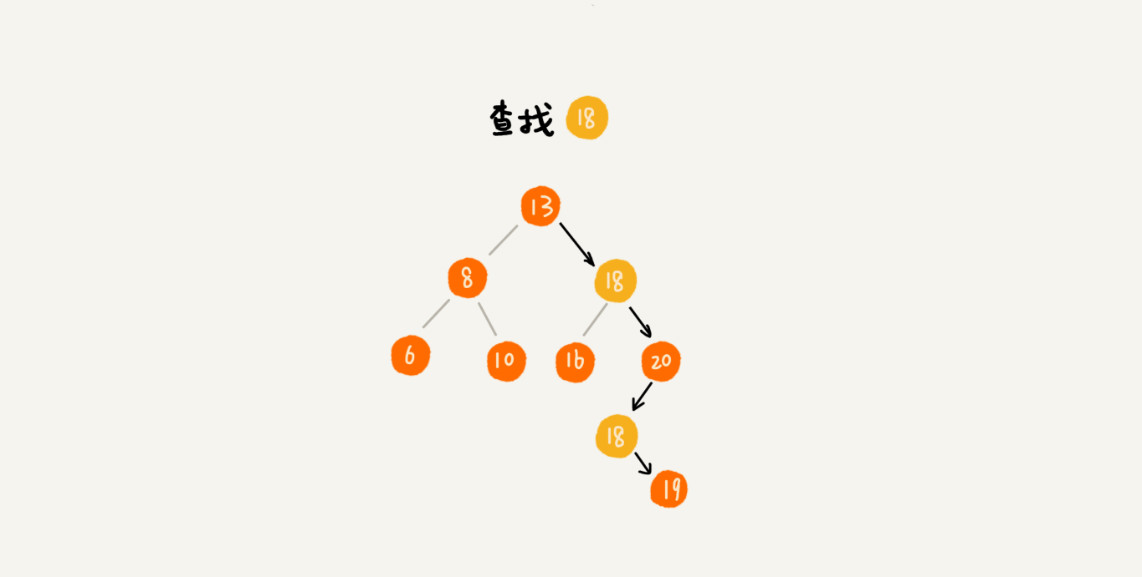
- 在查找数据的时候,遇到相同值的节点,并不停止查找操作,而是继续在右子树中查找,直到遇到叶子节点,才停止,这样就可以把键值等于要查找自的所有节点都找出来,示意图如下:
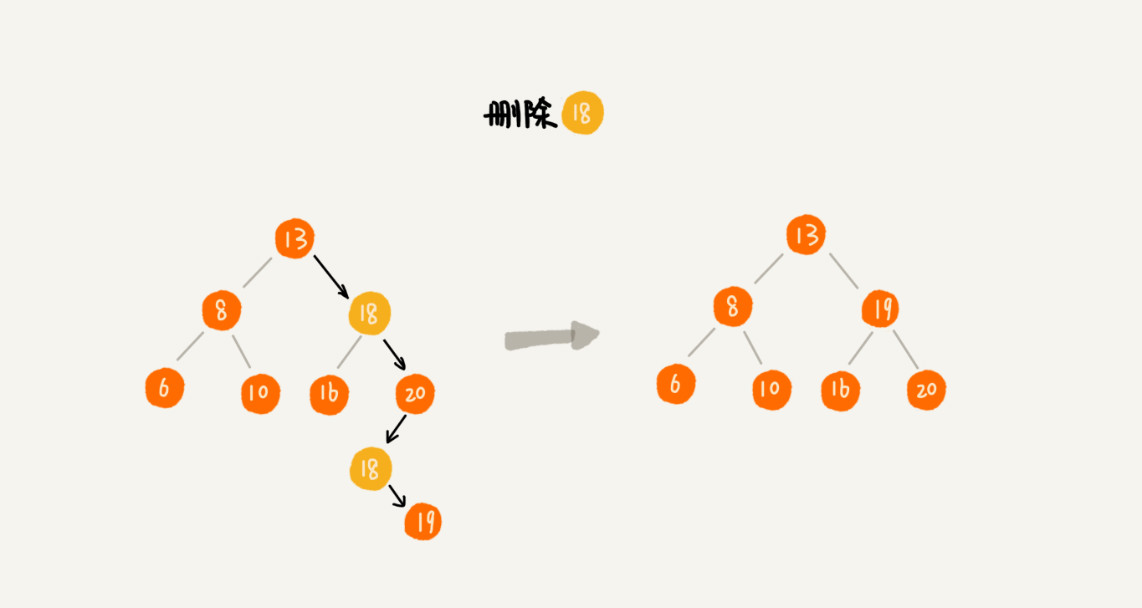
- 针对删除操作,先查找到所有要删除的节点,然后再按照上面删除操作的方法,递归依次删除,示意图如下:
- 如果遇到相同节点值,就将要插入的数据放到这个节点的右子树,即将新插入的数据当做大于这个节点的值来处理,示意图如下:
二叉查找树的时间复杂度
二叉查找树的排列不一样会导致查找、插入、删除的性能不一样,示意图如下:

可以看出最左边退化链表,最坏时间复杂度为O(n),二叉查找树的时间复杂度更树的高度成正比,即O(height)。如果一颗节点为n的完全二叉树,L是最大层数, n需要满足一个关系:
n >= 1+2+4+8+...+2^(L-2)+1
n <= 1+2+4+8+...+2^(L-2)+2^(L-1)
根据等比数列求和公式,L的范围是[log2(n+1),log2(n)+1],即一颗包含n个节点的完全二叉树的层数小于等于log2(n)+1,即高度小于等于log2(n)。
散列表 VS 二叉查找树
二叉查找树只有在平衡的情况下查找、插入、删除操作时间复杂度是O(logn),相比于散列表的优势:
- 散列表是无序存储的,想输出有序数据就需要进行排序。二叉查找树只需要中序遍历即可输出有序序列,时间复杂度是O(n)。
- 散列表扩容耗时很多,当遇到散列冲突时,性能不稳定。工程中使用平衡二叉查找树,时间复杂度稳定在O(logn)
- 某些情况下,哈希冲突的存在,哈希操作耗时,所以实际的查找速度不一定比O(logn)快
- 散列表构造比二叉查找树要复杂,需要考虑更多东西,平衡二叉树只需要考虑平衡性,解决方案比较成熟、固定
最后,为了避免过多的散列冲突,散列表转载因子不能太大,特别是基于开放寻址法解决冲突的散列表,不然会浪费一定的存储空间。
可以通过递归法求出一颗给定二叉树的确定高度: 根节点的高度 = max(左子树高度,右子树高度) + 1
红黑树 Red-Black Tree
红黑树是一种近似平衡的二叉查找树,它是为了解决二叉查找树在数据更新的过程中,复杂度退化的问题而产生的,红黑树的高度近似为log2(n),所以它是近似平衡,插入、删除、查找操作的时间复杂度都是O(logn)。
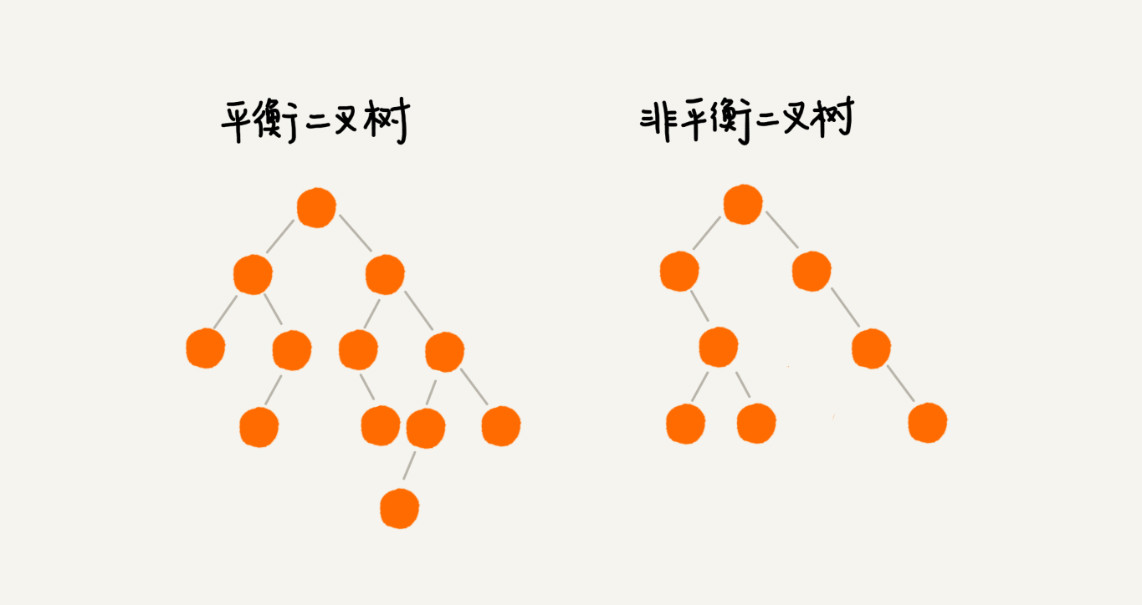
平衡二叉查找树指二叉树中任意一个节点的左右子树的高度相差不能大于1。完全二叉树、满二叉树都是平衡二叉树,但是非完全二叉树也有可能是平衡二叉树,示意图如下:
最先被发明的二叉查找树是AVL树,是一种高度平衡的二叉查找树。发明平衡二叉查找树这类数据结构的初衷是,解决普通二叉查找树在频繁的插入、删除等动态更新的情况下,出现时间复杂度退化的问题。
因此,平衡二叉查找树中”平衡“的意思,其实是让整棵树左右看起来比较对称,比较平衡,不要出现左子树很高、右子树很矮的情况,这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些。所以一个平衡二叉查找树,只要树的度不比log2(n)大很多如仍然是对数量级的,尽管不符合严格平衡二叉查找树的定义,但是仍然可以说是一个合格的平衡二叉查找树。
平衡二叉查找树有Splay Tree(伸展树)、(Treap)树堆等,但是平时常见的是红黑树。
红黑树,简称R-B Tree,是一种不严格的平衡二叉查找树,其中的节点,别标记为黑色和红色两类,还需要满足以下要求:
- 根节点是黑色的
- 每个叶子节点都是黑色的空节点(NIL),叶子节点不保存数据,主要是为了简化红黑树的代码实现而设置的
- 任何相邻的节点都不能同时为红色,即红色节点是被黑色节点隔开的
- 每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点
近似平衡的红黑树
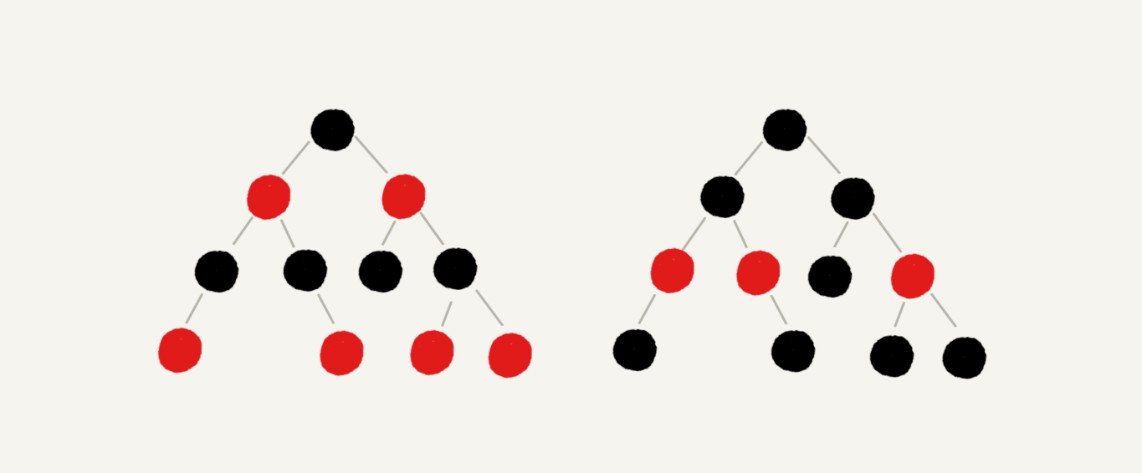
红黑树是近似平衡的,平衡的意思可以等价为性能不退化,”近似平衡“就等价为性能不会退化的太严重,红黑树的示意图如下J:
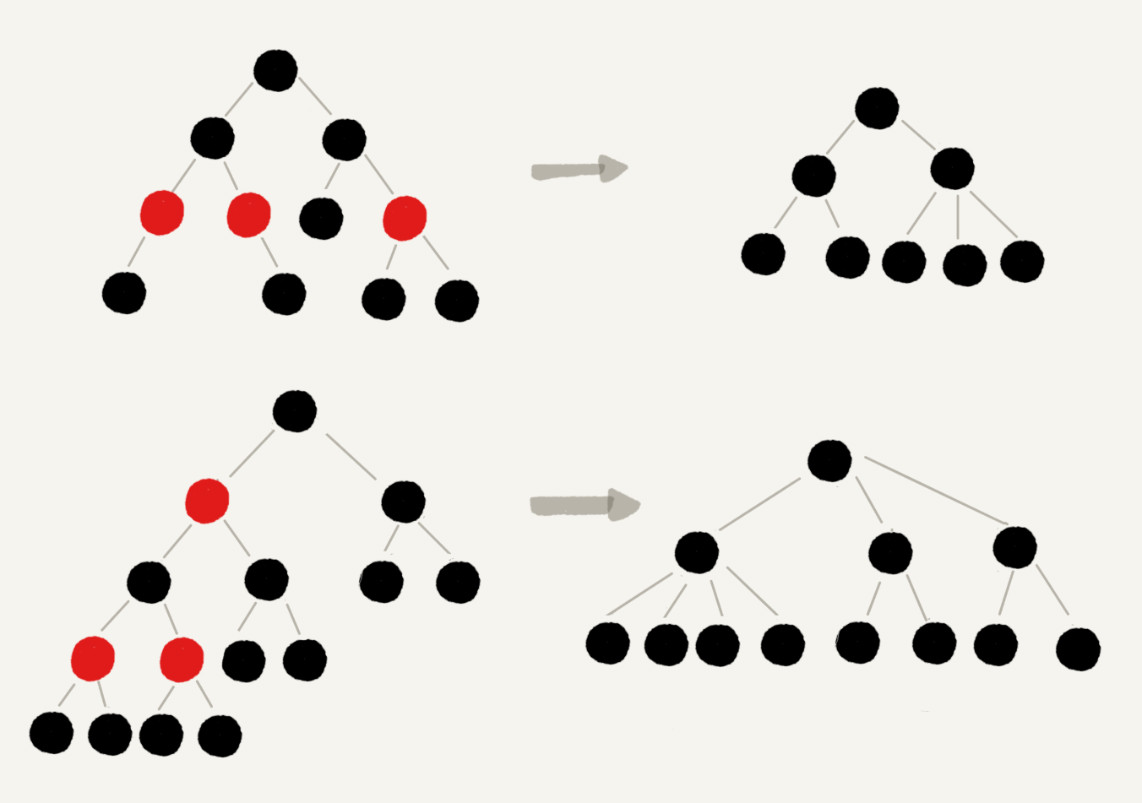
将红色节点从红黑树中去掉,单纯包含黑色节点的红黑树从原来的二叉树变成了四叉树,仅包含黑色节点的四叉树的高度,比包含相同节点个数的完全二叉树的高度还要小,因为完全二叉树的高度近似log2(n),所以四叉”黑树“的高度不会超过log2(n);由于红黑树要求的第三条,红黑树的最长路径不会超过2log2(n),因此,红黑树的高度近似为2log2(n),示意图如下:
红黑树的高度只比高度平衡的AVL树的高度log2(n)仅仅打了一倍,在性能上,下降的不多。这种推导不够精确,实际上红黑树的性能更好。
为什么红黑树很流行
主要原因有:
- Treap、Splay Tree,绝大部分情况下,操作的效率都很高,但是无法避免极端情况下时间复杂度的退化,对单次操作时间非常敏感的场景来说,并不适用
- AVL树是一种高度平衡的二叉树,查找效率非常高,但是为了维持平衡,每次插入、删除都需要调整,比较复杂和耗时,对于经常插入、删除的场合,代价过高
- 红黑树是近似平衡,在维护平衡的成本上,比AVL树低
最重要的是红黑树的插入、删除、查找各种性能都比较稳定,对于工程应用来说,更倾向与这种性能稳定的平衡二叉查找树。
红黑树的实现
左旋全称是叫围绕某个节点的左旋,右旋全称是围绕某个节点的右旋,示意图如下:
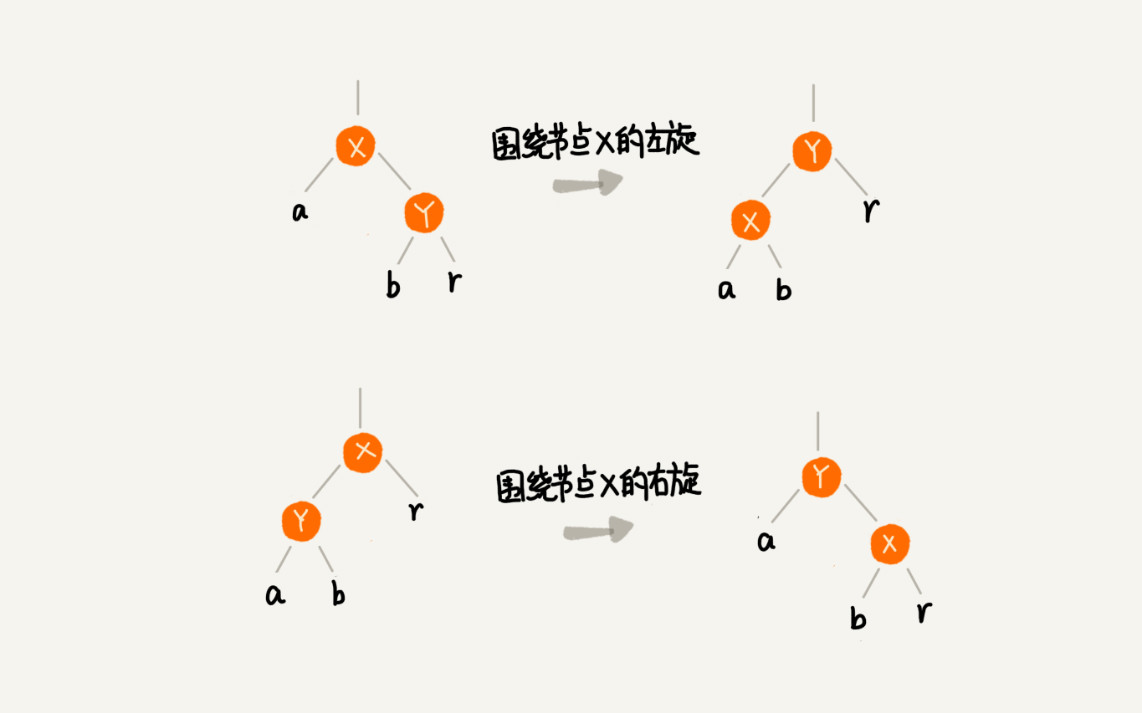
图中a,b,r表示子树,可以为空。
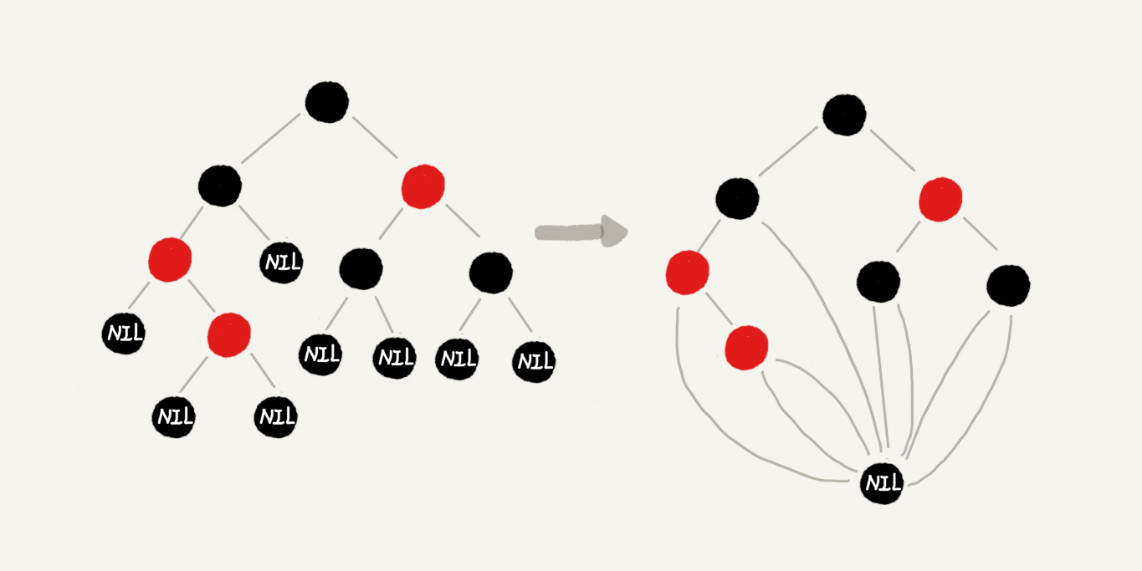
红黑树实现时每个叶子节点都是黑色的空节点用一个黑色节点存储表示就可以了,示意图如下:
对于红黑树的实现,需要:
- 把红黑树的平衡调整过程比作魔方复原,不要过于深究这个算法的正确性
- 找准关注节点,不要搞丢,搞错关注节点
- 插入操作的平衡调整比较简单,但是删除操作就比较复杂,有两次调整过程:
- 第一次是针对要删除的节点做初步调整,让调整后的红黑树继续满足第四条定义,但是第三条就不满足了
- 第二次调整是让红黑树满足第三条定义,即不存在相邻的红色节点
递归树
将递归过程分解为一层一层的节点画出来就是一棵树,叫做递归树,计算斐波那契数列的示意图如下:
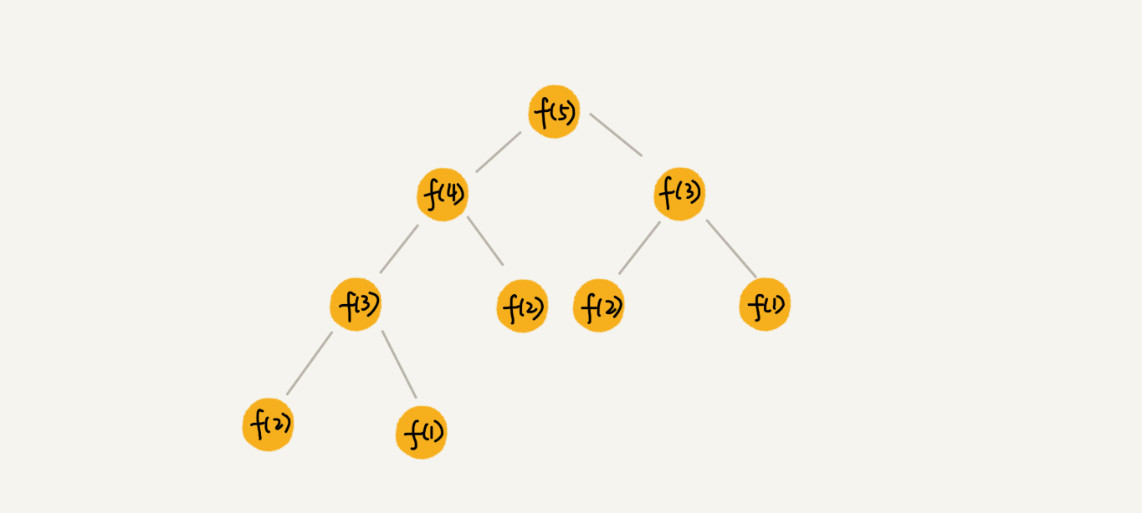
可以借助递归树分析递归算法的时间复杂度。
动态数据结构
散列表:插入删除查找都是O(1), 是最常用的,但其缺点是不能顺序遍历以及扩容缩容的性能损耗。适用于那些不需要顺序遍历,数据更新不那么频繁的。
跳表:插入删除查找都是O(logn), 并且能顺序遍历。缺点是空间复杂度O(n)。适用于不那么在意内存空间的,其顺序遍历和区间查找非常方便。
红黑树:插入删除查找都是O(logn), 中序遍历即是顺序遍历,稳定。缺点是难以实现,其实跳表更佳,但红黑树已经用于很多地方了,历史遗留的原因。
注:本文是《数据结构与算法之美》的读书笔记,配套代码地址GitHub。本文仅限个人学习,请勿用作商业用途,谢谢。
Note: Cover Picture