高性能数据库集群:读写分离
读写分离的本质是将访问压力分散到集群中的多个节点,但是没有分散存储压力,其基本原理是将数据库读写分散到不同的节点上,下面是其基本架构图:
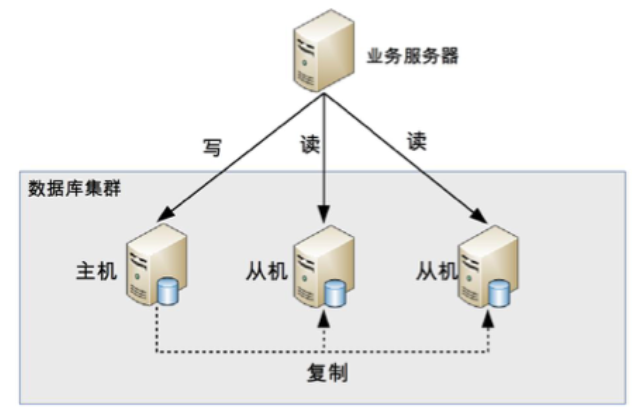
读写分离的基本实现是:
- 数据库服务器搭建主从集群,一主一从、一主多从都可以
- 数据库主机负责读写操作,从机只负责读操作
- 数据库主机通过复制将数据同步到主机,每台数据库服务器都存储了所有的业务数据
- 业务服务器将写操作发送给数据库主机,将读操作发送给数据库从机
注意:这里是主从集群而不是主备集群,前者是需要提供读数据的功能的,而后者一般认为仅仅提供备份功能,不提供访问功能,两者并不等价。
读写分离会引入两个设计复杂度:主从复制延迟和分配机制
主从复制延迟
解决方法有:
- 写操作后的读操作指定发送给数据库主服务器:该方式与业务强绑定,对业务的侵入和影响较大
- 读从机失败后再读一次主机:二次读取,与业务无绑定,只需要对底层数据库访问的API进行封装,实现代价小,但是会大大增加主服务器的读操作压力
- 关键业务读写操作全部指向主机,非关键业务采用读写分离
基本架构是:
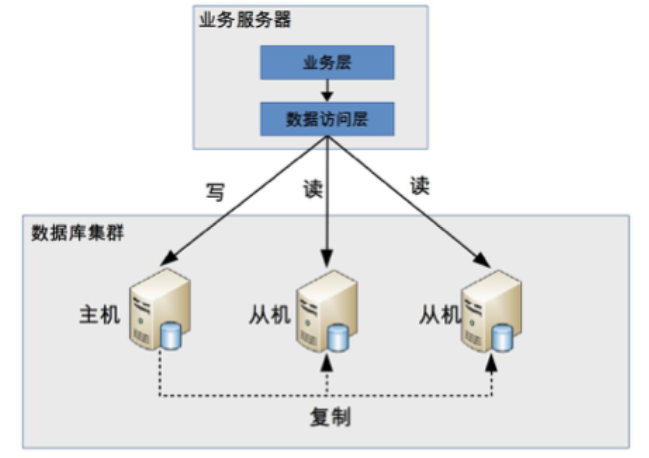
分配机制
将读写操作区分开,然后访问不同的数据库服务器,有两种方式:
- 程序代码封装:指在代码中抽象一个数据访问层or中间层封装,实现读写操作分离和数据库服务器连接的管理
- 中间件封装:指独立一套系统出来,实现读写操作分离和数据库服务器连接的管理
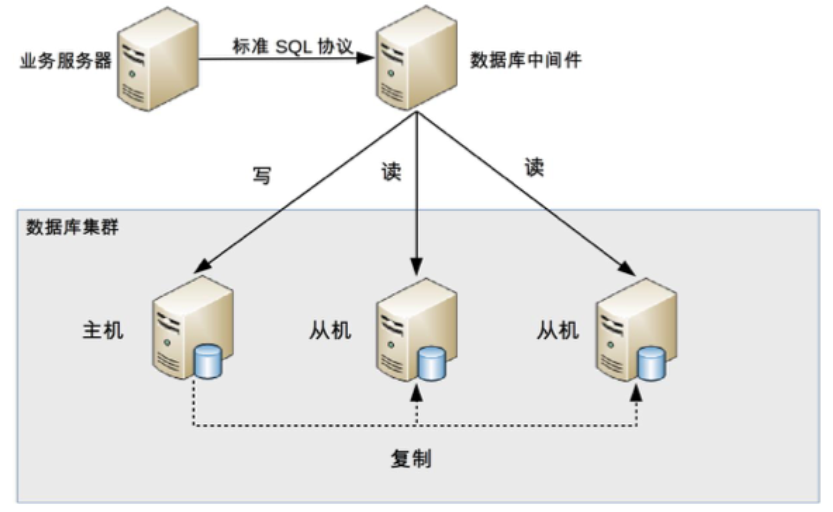
高性能数据库集群:分库分表
读写分离只是分散了数据库读写的操作的压力,但是分散存储能力,当数据量过大时,单台数据库服务器的存储能力会成为系统的瓶颈,主要体现在:
- 读写性能下降
- 数据库备份和恢复需要很长时间
- 极端情况下丢失数据的风险越高
因此,单个数据库存储的数据量不能太大,需要控制在一定的范围内,并且分散存储到多台数据库服务器上,常见方法有分库和分表。
业务分库
业务分库指的是按照业务模块将数据分散到不同的数据库服务器,示意图如下:
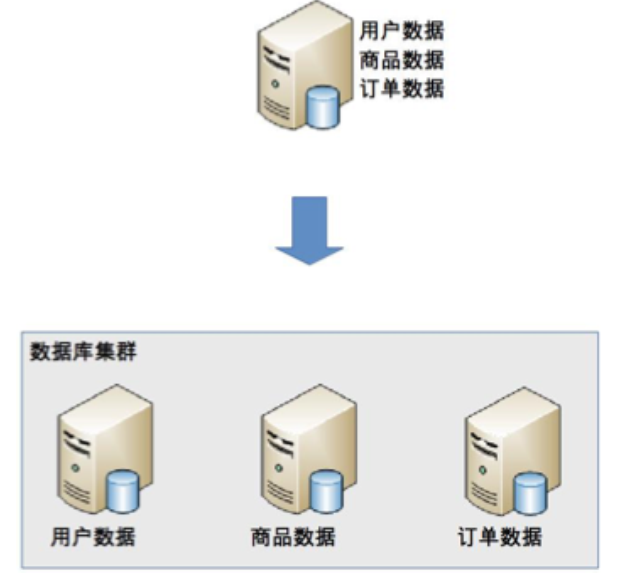
带来的问题:
- join操作问题:原本在同一个数据库的表分散到不同的数据库中,导致无法使用SQL的join查询
- 事务问题:原本在同一个数据库中不同的表可以在同一个事务中修改,业务分库后,表分散到不同的数据库中,无法通过事务统一修改
- 成本问题:数据库变多
分表
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但是当同一业务的单表数据达到单台数据库服务器的处理瓶颈时,就需要对表单数据进行拆分。
单表拆分分为垂直分表和水平分表,示意图如下:
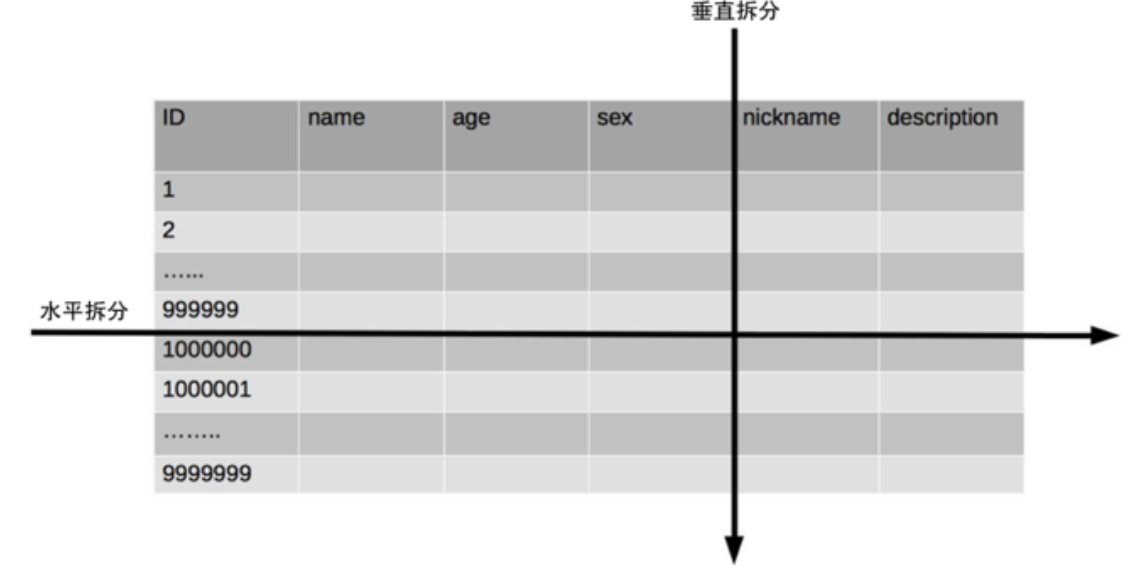
- 垂直拆分指将表记录数相同但包含不同的列
- 水平拆分指将表的列相同但包含不同的行数据
实际架构设计过程中并不局限拆分的次数。分表能够有效地分散存储压力和带来性能提升,但是也引入了各种复杂性:
- 垂直发表:适合将表中某些不常用且占了大量空间的列拆分出去
- 表操作的数量增加
- 水平分表:适合表行数特别大的数据
- 路由:需要增加路由算法进行计算某条数据具体属于哪个切分后的子表
- join操作需要在数据库中间件中进行多次join查询
- count操作
- order by操作
和数据库读写分离类似,分库分表具体的实现方式也是程序代码封装和中间件封装,但是实现更复杂。
高性能NoSQL
关系数据库存在的缺点如下:
- 存储的是行记录,无法存储数据结构
- Schema扩展很不方便:关系数据库的表结构Schema是强约束,操作不存在的列会报错业务变化扩充列需要执行DDL修改,修改过程可能长时间将表锁住
- 在大数据场景下I/O较高
- 全文搜索功能比较弱
常见的NoSQL方案分为4类:
- K-V存储:解决关系数据库无法存储数据结构的问题,以Redis为代表
- 文档数据库:解决关系数据库强Schema约束问题,以MongoDB为代表
- 列式数据库:解决关系数据库大数据场景下的I/O问题,以HBase为代表
- 全文搜索引擎:解决关系数据库的全文搜索性能问题,以Elasticsearch为代表
Redis
Redis是K-V存储的典型代表,是一款开源基于BSD许可的高性能K-V缓存和存储系统。Redis的Value是具体的数据结构,包括String、Hash、List、Set、Sorted Set、BitMap和Hyperloglog,也常被称为数据结构服务器。
Redis的缺点是并不支持完整的ACID事务,Redis虽然提供事务功能,但是与关系数据库的事务相比差太多,主要是Redis的事务只能保证隔离性和一致性(I和C),无法保证原子性和持久性(A和D)。
文档数据库
文档数据库最大的特点就是no-schema,可以存储和读取任意的数据,目前大部分数据格式是JSON或者BSON。因为JSON数据是自描述的,无须再使用前定义字段,读取操作也不会导致SQL那样的语法错误。
文档数据库的主要优势:
- 新增字段简单:程序代码直接读写即可
- 历史数据不会出错:不存在返回空值,代码做兼容处理即可
- 很容易存储复杂数据:JSON能够描述复杂的数据结构,特别是和电商和游戏这类的业务场景
文档数据库的缺点是不支持事务,某些对事务要求严格的业务场景是不能使用文档数据库的。无法实现关系数据库的Join操作。
列式数据库
列式数据库是按照列来存储数据的数据库,与之对应的传统关系数据库被称为行式数据库,因为关系数据库是按照行来存储数据的。
对海量数据进行统计时,列式数据库只需要读取特定的感兴趣列,而不需要全部读取行数据,节省I/O;因为单个列的数据相似度相比行来说更高,所以列式数据库具有更高的存储压缩比,能够节省更多的存储空间。行:3:1到5:1,列:8:1到30:1。
列式数据库的随机写效率要远远低于行式存储的写效率。
一般将列式存储应用在离线的大数据分析和统计场景中,因为这种场景主要是针对部分单列进行操作,且数据写入后就无须再更新删除。
全文搜索引擎
传统的关系型数据库通过索引来达到快速查询的目的。全文搜索的条件可以随意组合,索引会非常多,模糊匹配方式,索引无法满足,只能通过Like查询,而like查询是整表扫描,效率非常低。
全文搜索引擎的技术原理被称为“倒排索引”(Inverted Index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,其基本原理是建立单词到文档的索引。
正排索引的基本原理是建立文档到单词的索引,适用于根据文档名称来查询文档内容。倒排索引适用于根据关键词来查询文档内容。
全文搜索引擎的索引对象是单词和文档,而关系数据库的索引对象是键和行。
Elasticsearch是分布式的文档存储方式,它能存储和检索复杂的数据结构——序列化称为JSON文档——以实时的方式。
高性能缓存架构
缓存的基本原理是将可能重复使用的数据放到内存中,一次生成、多次使用,避免每次使用都去访问存储系统。
缓存穿透
缓存穿透是指缓存没有发挥作用,业务系统虽然去缓存查询数据,当缓存中没有数据,业务系统需要再次去存储系统查询数据,通常有:
- 存储数据不存在
- 缓存数据生成耗费大量时间或者资源
缓存雪崩
缓存雪崩是指当缓存失效(过期)后引起系统性能急剧下降的情况。解决方法有:
- 更新锁机制
- 后台更新
缓存预热是指系统上线后,将相关的缓存数据直接加载到缓存系统,而不是等待用户访问才来触发缓存加载。
缓存热点
缓存热点的解决方案是复制多份缓存副本,将请求分散到多个缓存服务器上,减轻缓存热点导致的单台缓存服务器压力。不同缓存副本的过期时间是指定范围内的随机值。
Note: Cover Picture