Meta-reinforcement Learning
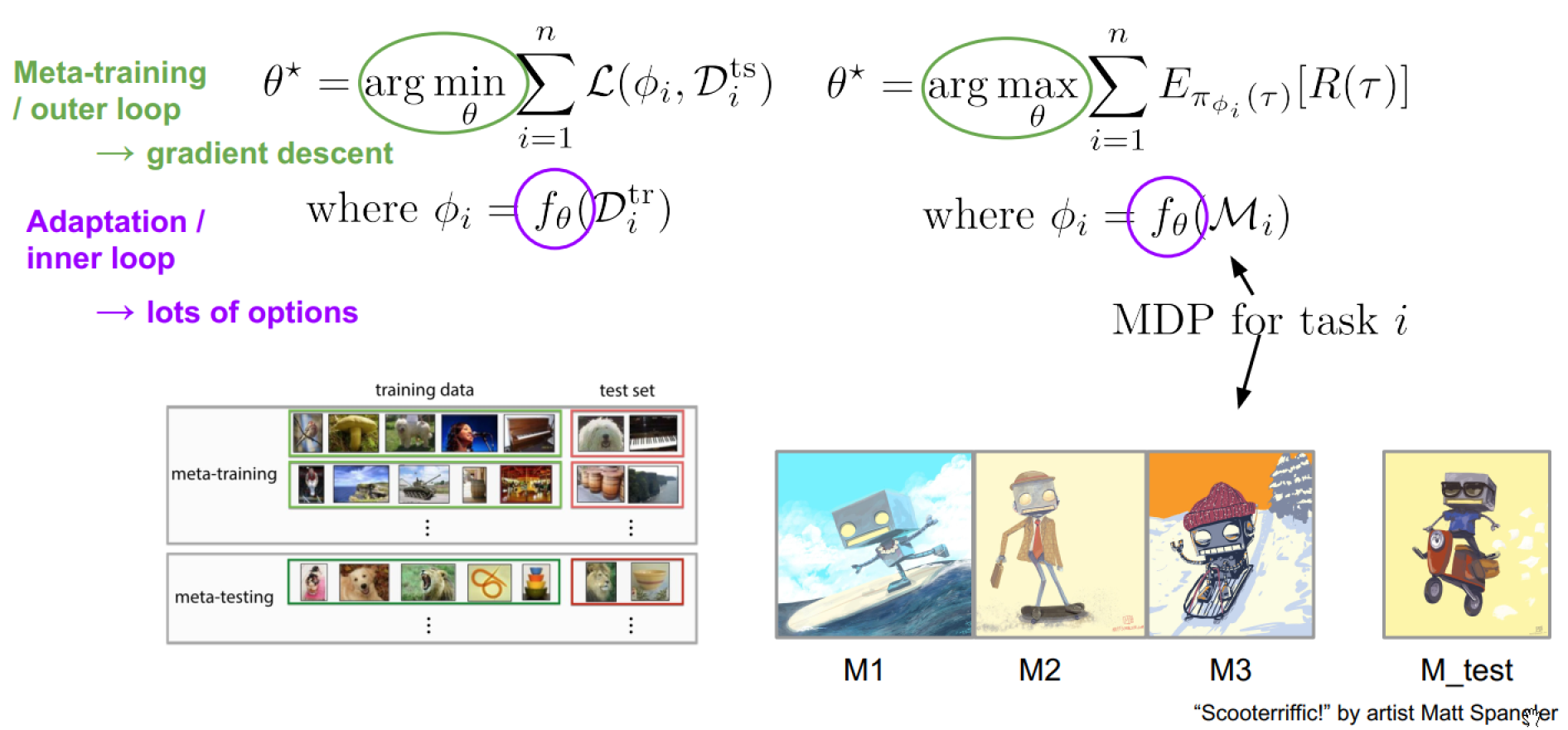
For meta learning, the adaptation data is given to us. But for reinforcement learning, the agent has to collect adaptation data.
Recurrent vs Gradient
Implement the policy as a recurrent network, train across a set of tasks.
Pro: general, expressive Con: not consistent
Persist the hidden state across episode boundaries for continued adaptation.
Implement the policy using policy gradient.
Pro: consistent Con: not expressive
How these Algorithms Learn to Explore
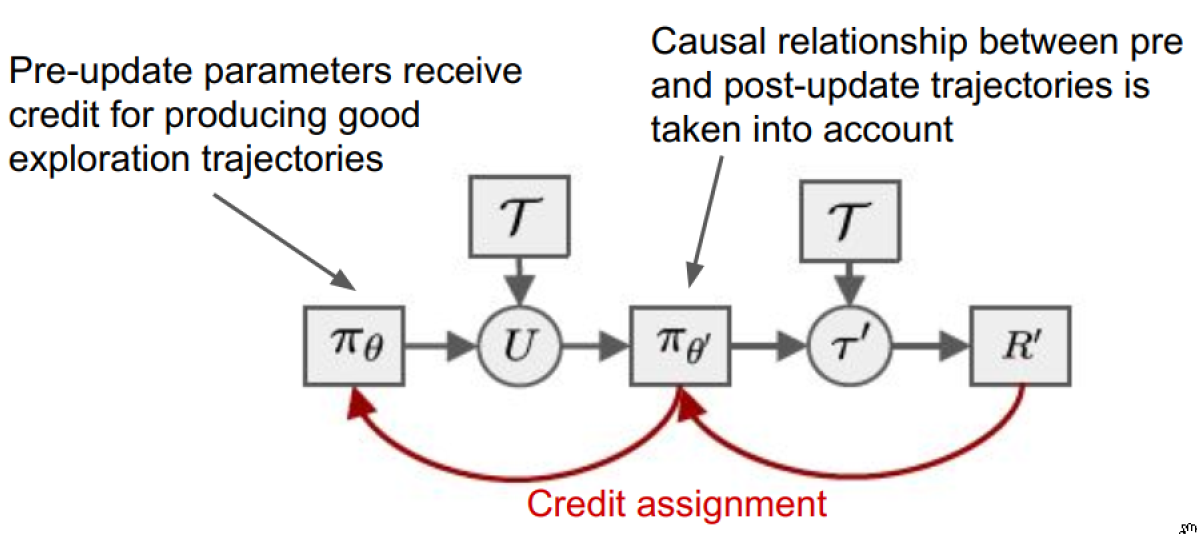
Exploration requires stochasticity, optimal policies don’t.
Typical methods of adding noise are time-invariant.
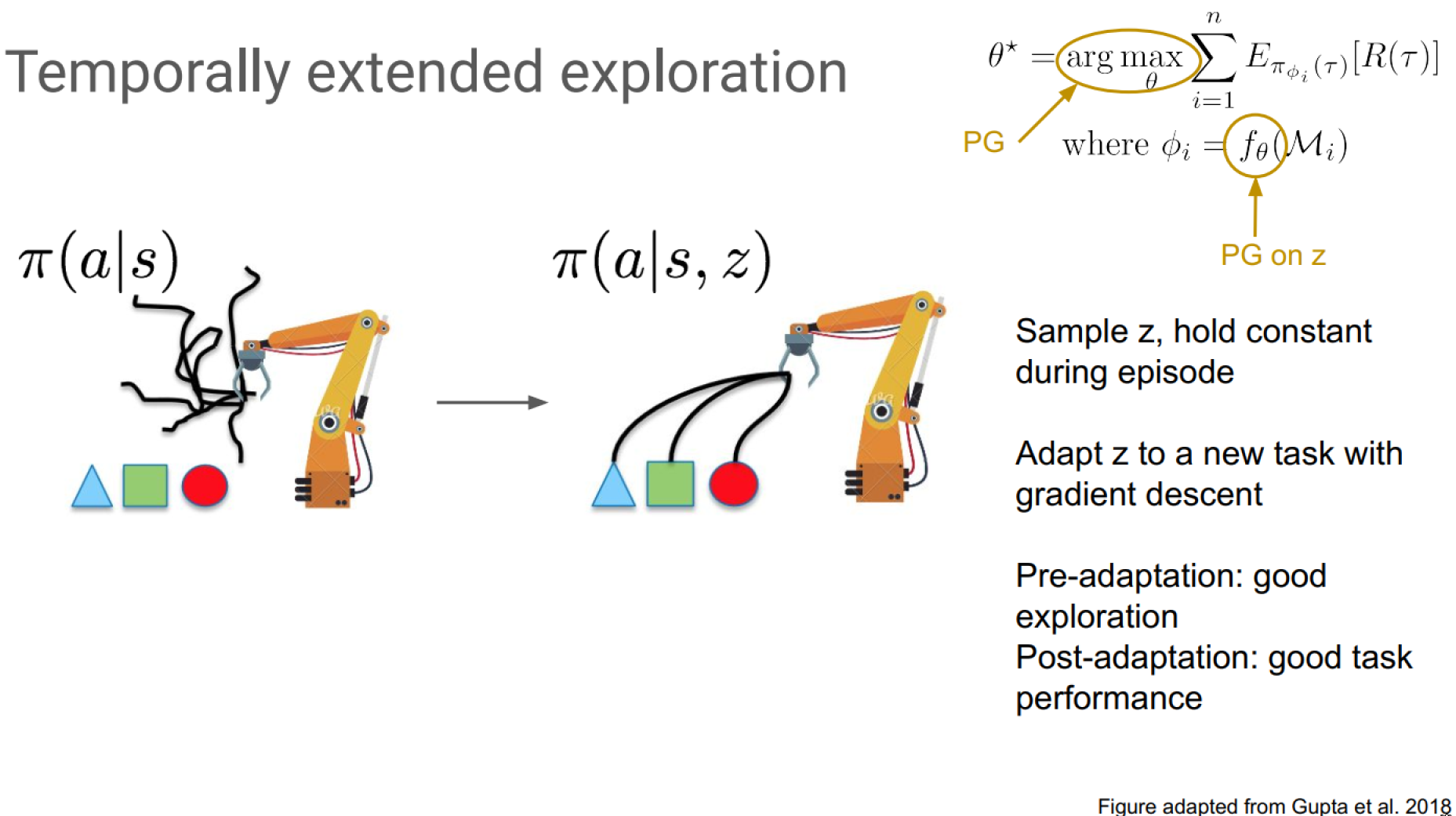
Temporally extended exploration with MAESN:
See more from MAESN
Difference of Meta-RL Approaches
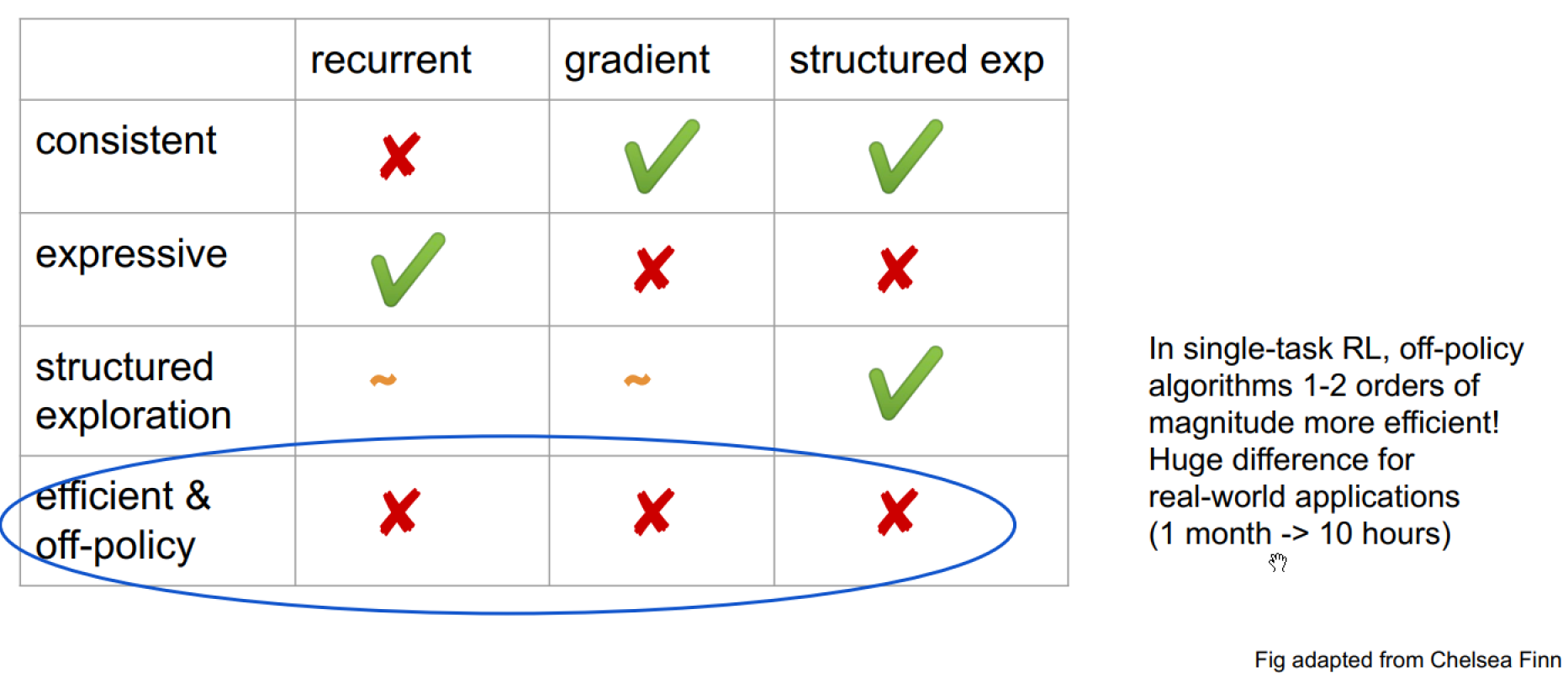
Why is Off-policy Meta-RL Difficult

PEARL
POMDP
State is unobserved(hidden). Observation gives incomplete information about the state, e.g. incomplete sensor data.
Model belief over latent task variables
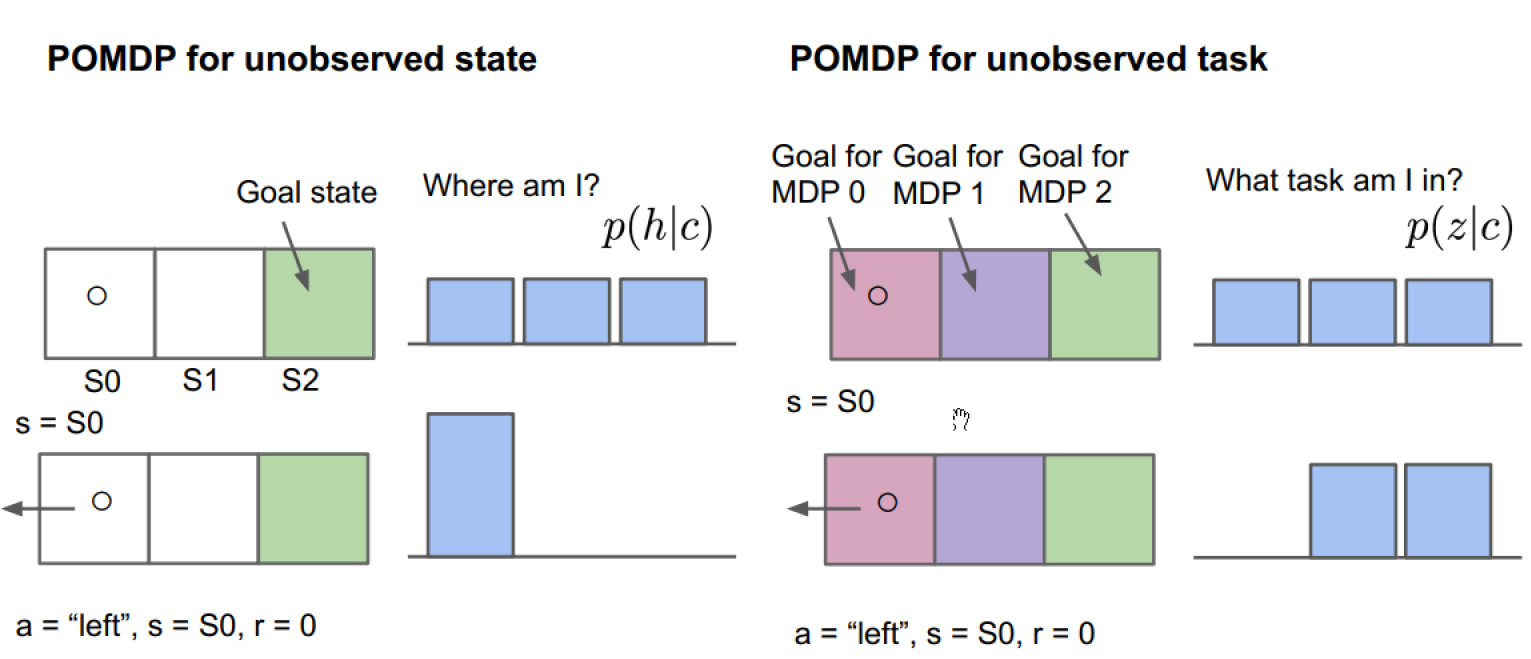
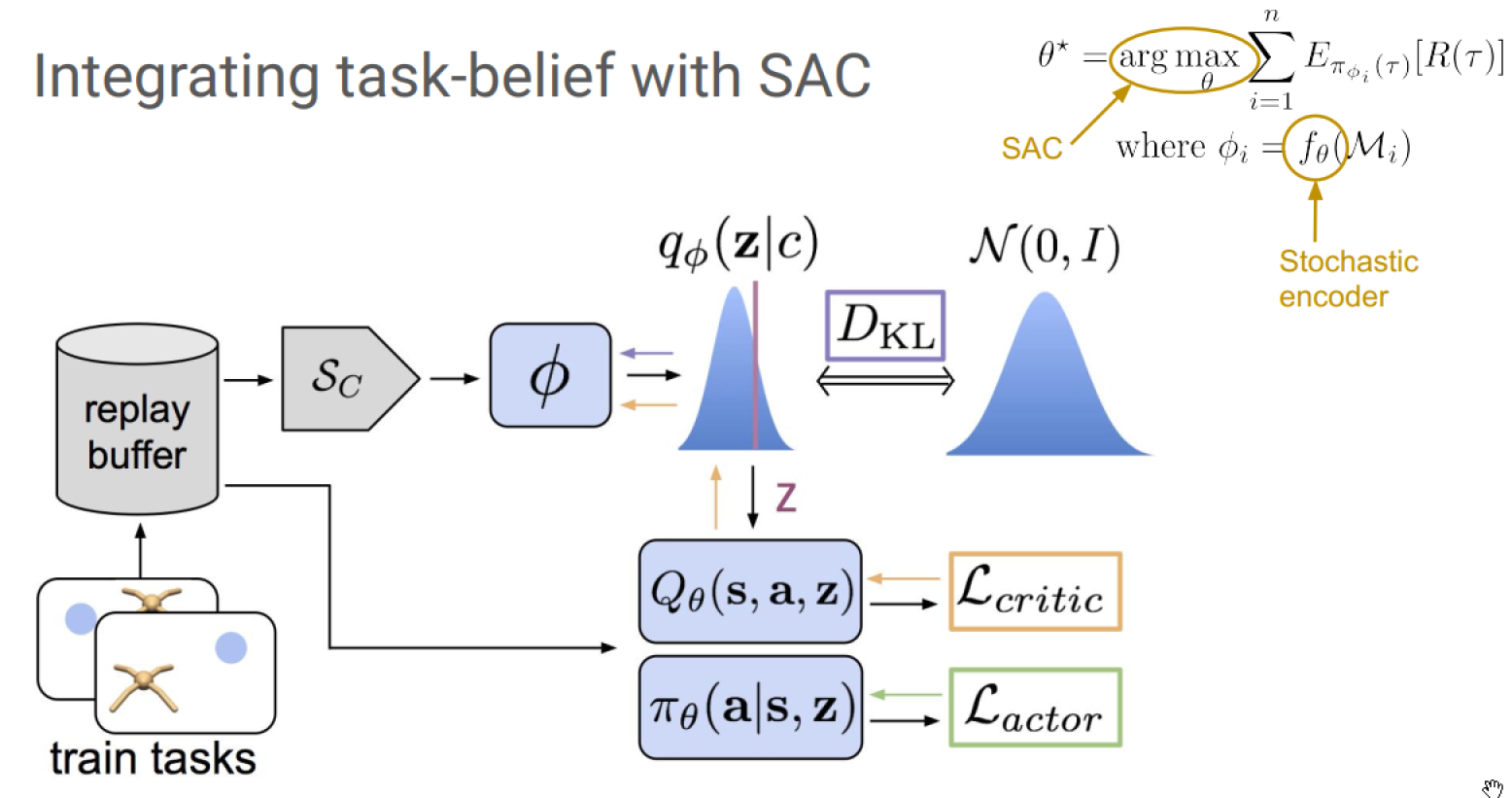
RL with task-belief states
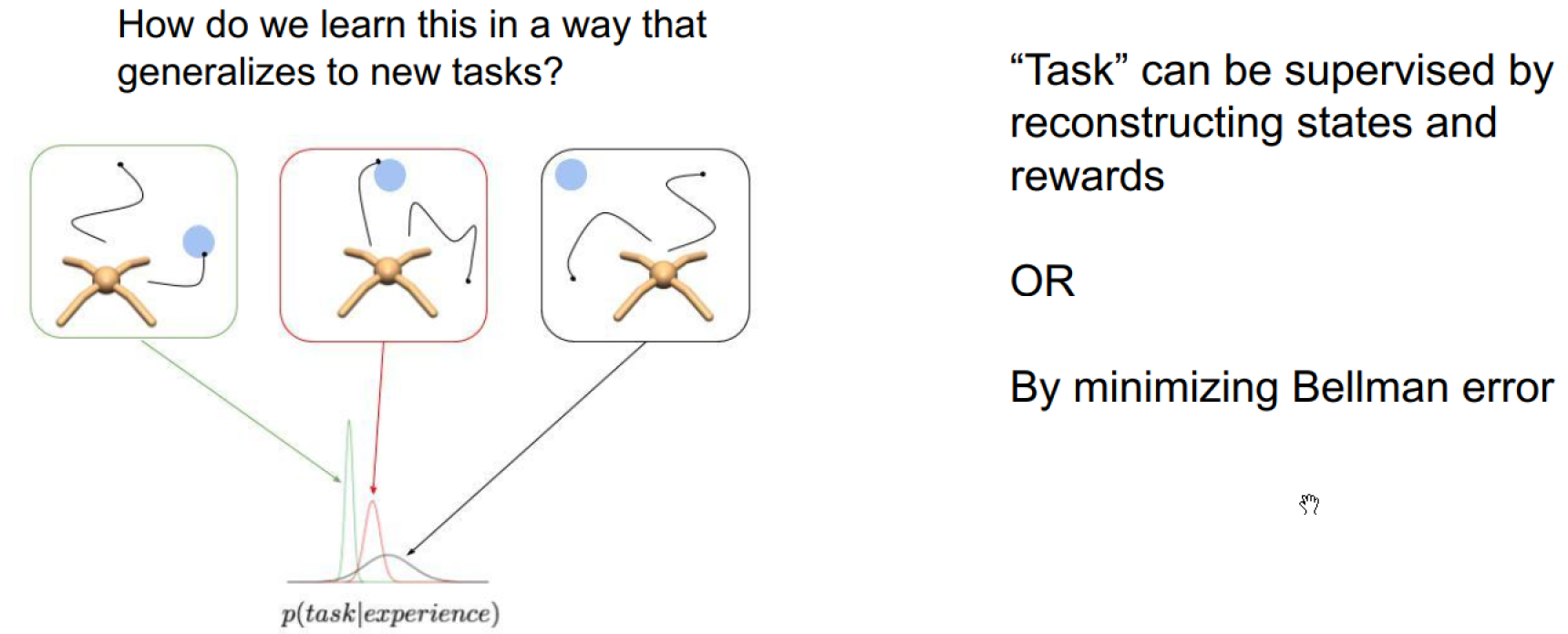

Encoder design:
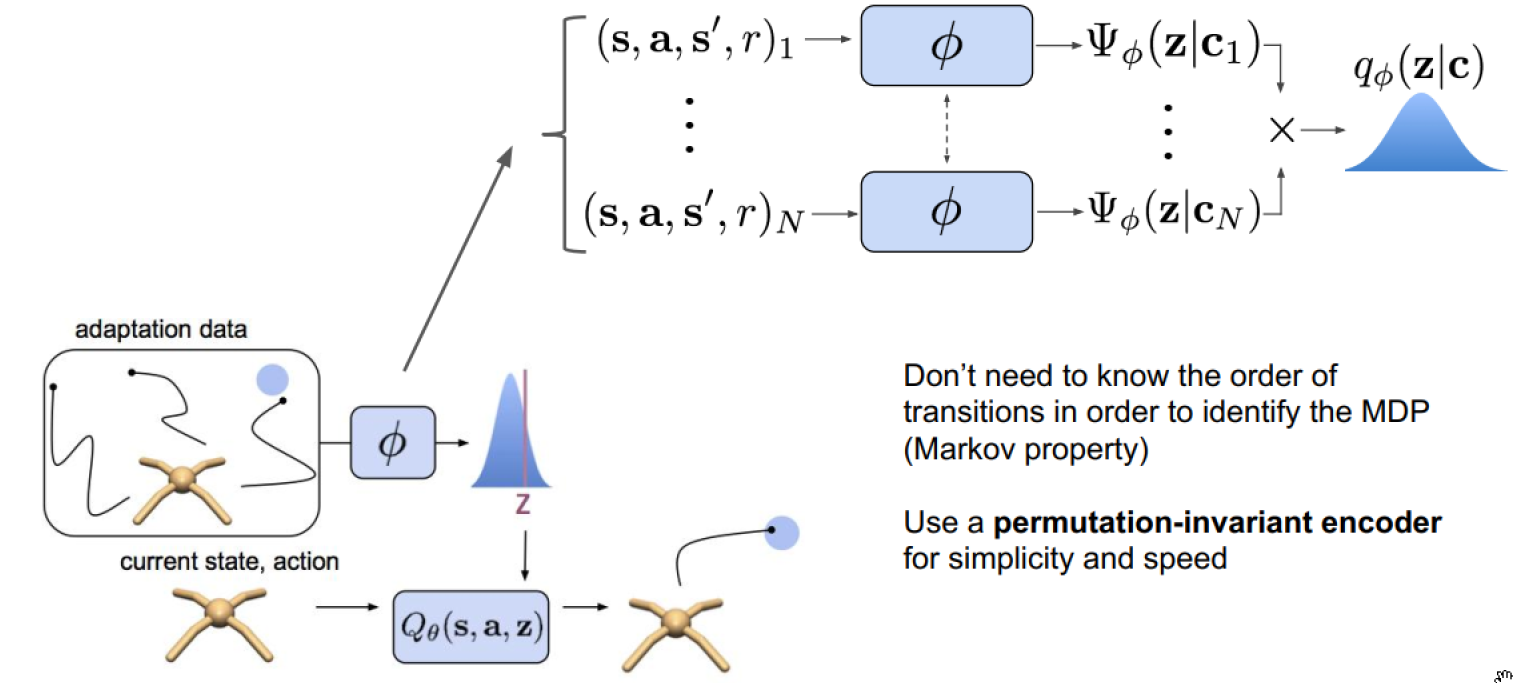
SAC
See more from Soft Actor-Critic.

Integrating Task-belief with SAC
Summary
- Building on policy gradient RL, we can implement meta-RL algorithms via a recurrent network or gradient-based adaptation
- Adaptation in meta-RL includes both exploration as well as learning to perform well
- We can improve exploration by conditioning the policy on latent variables held constant across an episode, resulting in temporally-coherent strategies.
- Meta-RL can be expressed as a particular kind of POMDP
- We can do meta-RL by inferring a belief over the task, explore via posterior sampling from this belief, and combine with SAC for a sample efficient algorithm.
Note: Cover Picture