Data Distributions of Tasks for Meta-Training
如果元训练的数据分布不当,会造成模型忘记完成特定任务的能力。
比如在姿态估计任务中:

Meta-regularization(MR)
Minimize meta-training loss + information in $\theta$:
$$ L(\theta, D_{meta-train}) + \beta D_{KL}(q(\theta;\theta_\mu,\theta_\sigma) || p(\theta)) $$
Places precedence on using information from $D_{i}^{tr}$ over $\theta$.
Can combine with your favorite meta-learning algorithm.

Unsupervised Meta-RL
General Recipe:
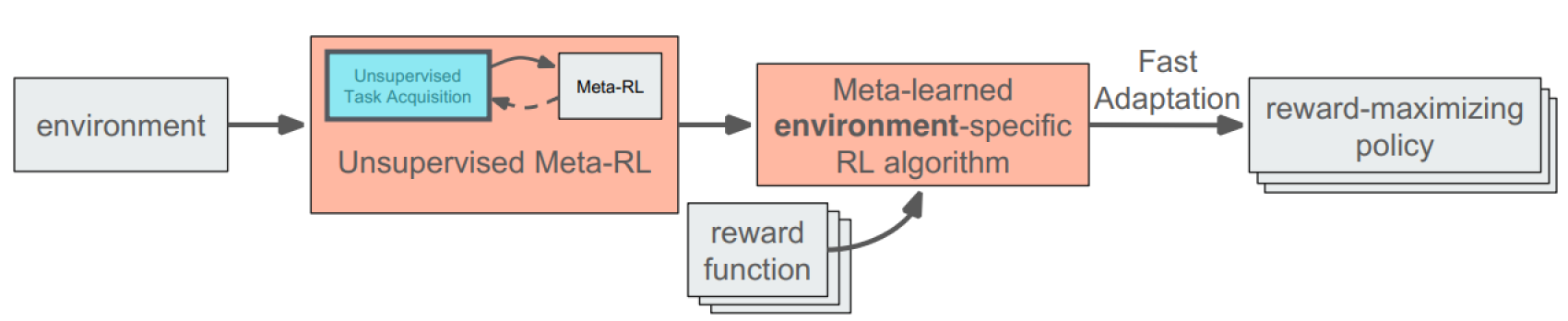
Random Task Proposals
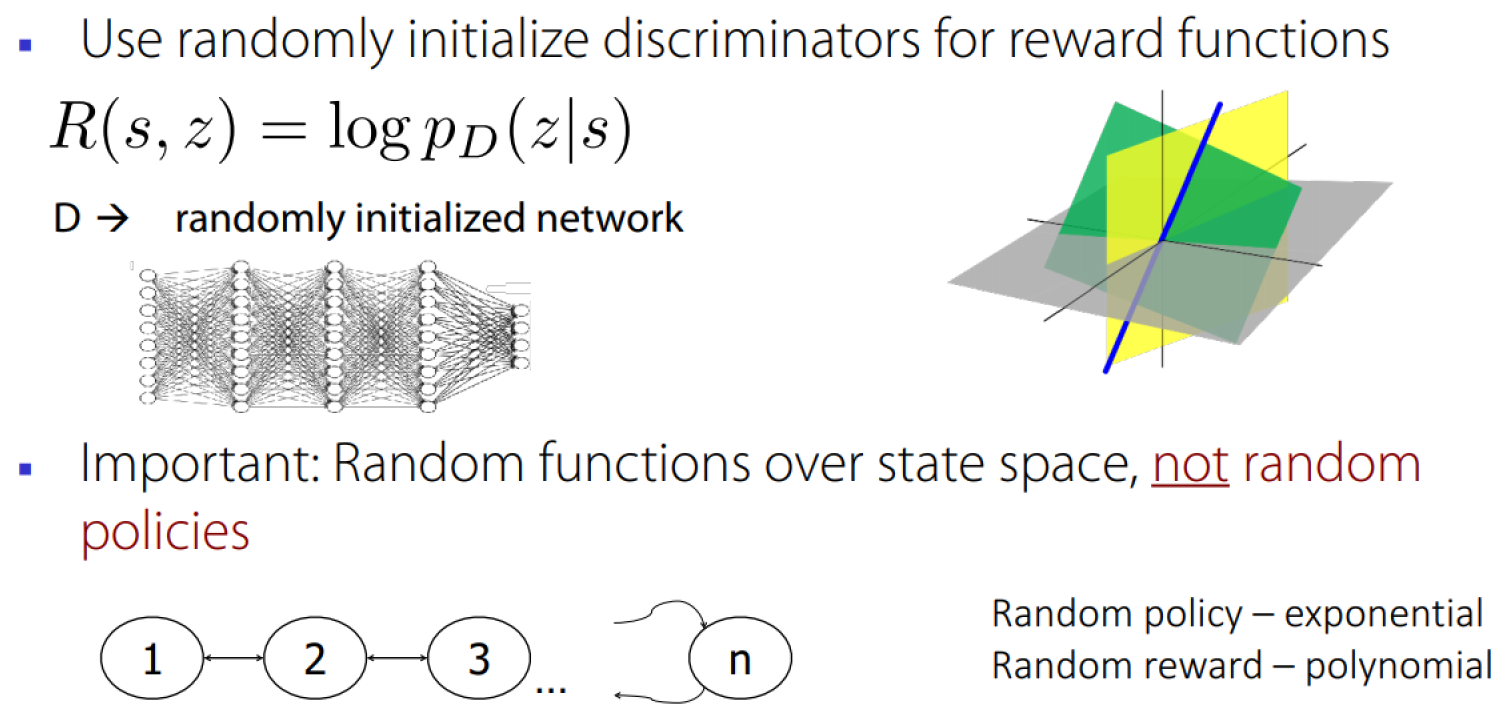
Diversity-Driven Proposals

See more from Diversity is All You Need
Relatively simple mechanisms for proposing tasks work surprisingly well.
Section Summary
We can Learn Prior for Few-shot Adaptation Using:
- Non-mutually exclusive tasks, through meta-regularization
- From unsegmented time series, via ene-to-end change-point detection
- From unlabeled data and experience, using clustering
Can We Meta-Learn Across Task Families
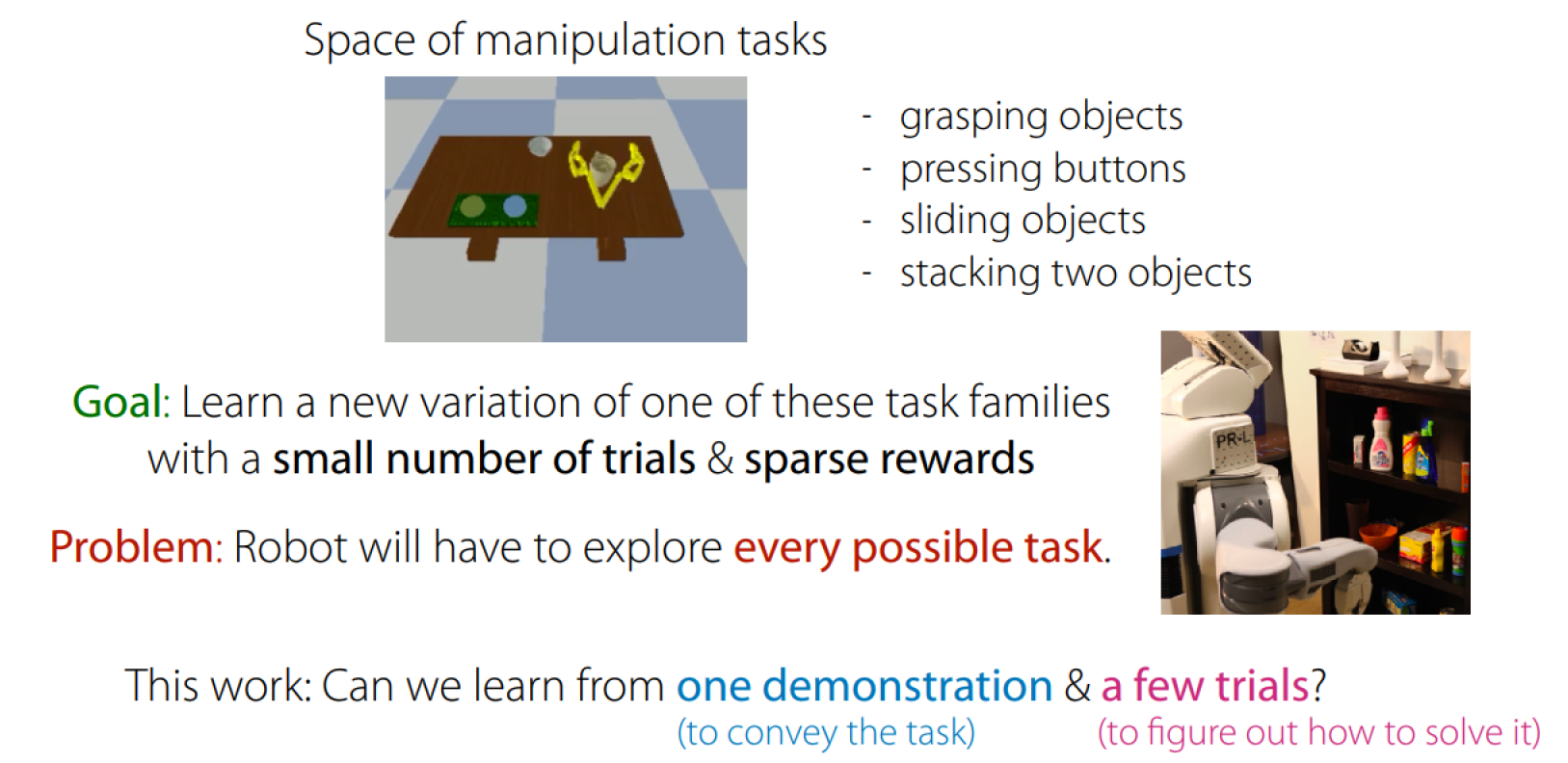
Key idea:
- Watch one task demonstration
- Try task in new situation
- Learn from demo & trial to solve task
How can we train for this in a scalable way?
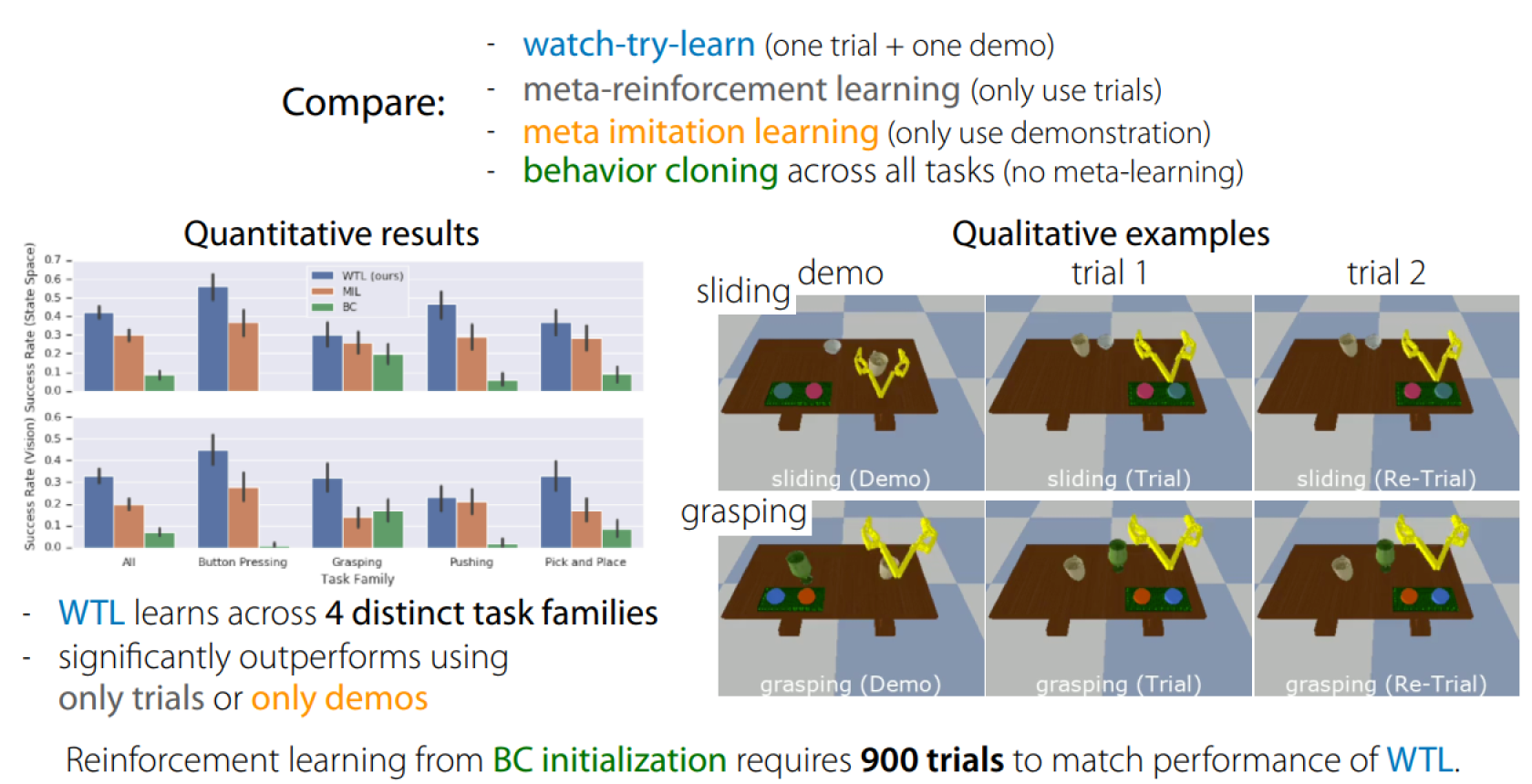
- Collect a few demonstrations for many different tasks
- Train a one-shot imitation learning policy
- Collect trials for each task by running one-shot imitation policy(batch off-policy collection)
- Train “re-trial” policy through imitation objective: $D_{train}: demo + trial(s)$
Performance:
Meta-World Benchmark
Meta-learning and Multi-task RL algorithms seem to struggle.
- All tasks individually solvable
- All methods given budget with plenty of samples
- All methods plenty of capacity
Training models independently performs the best.
See more from Meta-world benchmark.
This must be an optimization challenge.
Solution:
Gradient Surgery for Multi-task Learning.
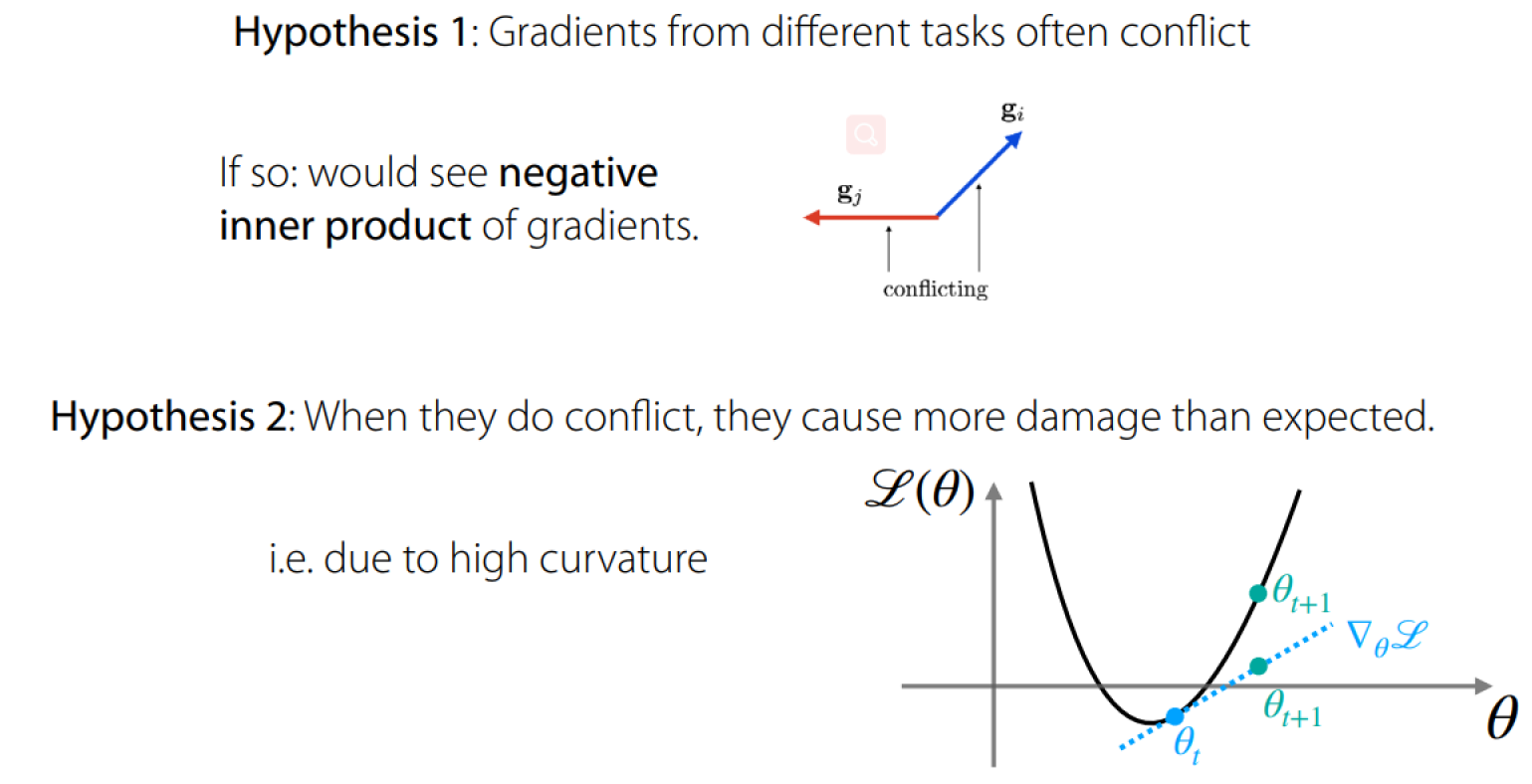
What does It Take to Run Multi-Task & meta-TL Across Distinct Tasks
Scaling to broad task distributions is hard, can’t be taken for granted:
- Convey task information beyond reward (e.g. a demo)
- Train on broad, dense task distributions like Meta-World
- Avoid conflicting gradients
Open Challenges in Multi-Task and Meta Learning

Machine are specialists, but humans are generalists.
Something Covered in CS330
- Learn multiple tasks(multi-task learning)
- Leverage prior experience when learning new things(meta-learning)
- Learn general-purpose models(model-based RL)
- Prepare for tasks before you know what they are(exploration, unsupervised learning)
- Perform tasks in sequence(hierarchical RL)
- Learn continuously(lifelong learning)
Note: Cover Picture