What is It
RLBench is an ambitious large-scale benchmark and learning environment featuring 100 unique, hand-design tasks, tailored to facilitate research in a number of vision-guided manipulation research areas, including: reinforcement learning, imitation learning, multi-task learning, geometric computer vision, and in particular, few-shot learning. — From the official website
Features
- 100 completely unique, hand-designed tasks:
- Ranging in difficulty, from simple target reaching and door opening, to longer multi-stage tasks, such as opening an oven and placing a tray in it
- Each task comes with a number of textual descriptions and an infinite set of demonstrations using waypoint-based motion planning
- Observations:
- Proprioceptive
- Joint angles
- Joint velocities
- Torques
- The gripper pose
- Visual: an over-the-shoulder stereo camera and an eye-in-hand monocular camera
- rgb
- depth
- segmentation masks
- Proprioceptive
The scene in the V-REP environment:
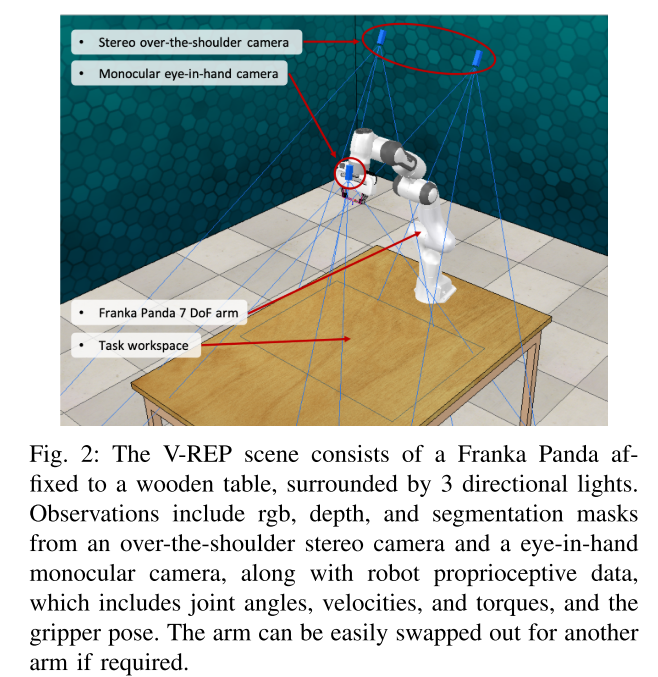
Important Notes
RLBench employs 3 keys terms: Task, Variation, and Episode.
- Each task consists of one or more variations
- From each variation, an infinite number of episodes can be drawn
- Each variation of a task comes with a list of textual descriptions that verbally summaries this variation of the task, which could prove useful for human robot interaction (HRI) and natural language processing (NLP) research
Each task has a completely sparse reward of +1 which is given only on task completion.
Users have a wide variety of action spaces at their disposal, which include:
- Absolute or delta joint velocities
- Absolute or delta joint positions
- Absolute or delta joint torque
- Absolute or delta end-effector velocities
- Absolute or delta end-effector poses
Building New Tasks
Each task has 2 associated files: a V-REP model file (.ttm), which holds all of the scene information and demo waypoints, and a python (.py) file, which is responsible for wiring the scene objects to the RLBench backend, applying variations, defining success criteria, and adding other more complex task behaviors.
Note: Cover Picture