Differences between TF 1.0 and TF 2.0
- Keras API is now the standard
- Other layers are gone
- tf.contrib is gone
- To create your own layers and models, subclass the Keras Layer/Model
- Sessions are gone
- Eager execution is enabled by default
- Meaning no placeholders, session.run(), tf.global_variables_initializer()
- Use
@tf.functionfor the efficiency of compiled graphs
Basic Operations
Data Container
- List: 任意类型
- np.array:相同类型的数据
- tf.Tensor:相同类型,快速计算
What’s Tensor
- Scalar: 1.1 dim=0
- Vector: [ 1.1 ], [1.1, 2.2, …] dim=1
- Matrix: [[1.1, 2.2], [ 3.3,4.4 ], [5.5, 6.6]] dim = (3,2)
- Tensor: rank > 2
TF is a Computing Lib
- int, float, double
- bool
- string
Tensor Property
详见Code
with tf.device('cpu'):
a = tf.constant([1])
with tf.device('gpu'):
b = tf.range(4)
c = np.arange(5)
- a.device:查看数据存储在cpu还是gpu上面
- a.gpu():将数据转换到gpu上
- a.cpu():将数据转换到cpu上
- a.numpy():将张量数据转换为numpy类型
- a.ndim:查看数据维度
- a.dtype:查看数据类型
- isinstance(a, tf.Tensor) or tf.is_tensor(a):检查数据类型,不推荐使用
- tf.is_tensor(a):检查数据是否是张量
- tf.rank(a):查看数据矩阵的秩
- tf.constant():创建常量张量
- tf.constant(1): 创建常量标量
- tf.constant([1]): 创建常量1维向量
- tf.convert_to_tensor(c, dtype=tf.int32):将array数据转换为张量
- tf.cast(a, dtype=tf.float64):对张量数据进行类型转换
- d = tf.Variable(a, name=‘input_data’): 创建一个名称为input_data的变量,初始数值为a,实际上是一个Tensor被包裹为变量,多了一些特殊属性,如trainable
Create Tensor
详见Code
- from numpy, list
- tf.convert_to_sensor()
- zeros, ones:创建0, 1张量
- tf.zeros()
- tf.zeros_like()
- tf.ones()
- tf.ones_like
- fill:创建元素都为某个值的张量
- tf.fill
- random:创建具有某个分布的张量
- tf.random.normal([ 2,2 ], mean=1, stddev=1)
- 正态分布:默认为均值0,方差1
- tf.random.truncated_normal([2,2], mean=0, stddev=1)
- 截断分布,因为在神经网络中,存在梯度消散的现象,将正态分布的左右两边截断,靠近中间采样
- tf.random.uniform([2,2] , minval=0, maxval=1)
- 在[minval, maxval]之间的均匀分布中采样
- Application
# [10, 28, 28, 3]: 图片数据,按照第一维度对64进行随机排序
idx = tf.range(10)
print('Original idx: ', idx)
idx = tf.random.shuffle(idx)
print('Shuffled idx: ', idx)
a = tf.random.normal([10, 784])
b = tf.random.uniform([10], maxval=10, dtype=tf.int32)
print(f'Original a: {a}')
print(f'Original b: {b}')
# Random Permutation
a_shuffled = tf.gather(a, idx)
b_shuffled = tf.gather(b, idx)
print(f'a shuffled: ', a_shuffled)
print(f'b shuffled: ', b_shuffled)
Typical Dim Data
- []
- 0, 1., 2.2…
- Scalar
- loss=mse(out, y)
- accuracy
- [d]
- [out_dim]
- Vector
- Bias
- [h,w]
- Matrix
- input x: [b, vec_dim]
- weight: [input_dim, output_dim]
- [b, len, vec]
- [b, 5, 5]
- Tensor
- x: [b, seq_len, word_dim]
- [b,h,w,c]
- Tensor
- Image: [b, h, w, 3]
- Feature maps: [b, h, w,c]
- [t,b,h,w,c]
- Single task: [b, h, w, 3]
- Meta-learning: [task_b, b, h, w, 3]
Indexing and Slicing
Indexing
详见Code
- Basic indexing
- [idx][idx][idx]
- Same with numpy
- [idx, idx, …]
- start:end
- start:end:step
- …
Selective Indexing
- data = [classes, students, subjects]
- tf.gather
- 代表从单个axis上挑选位于index的数据
- tf.gather(data, axis=0, indices=[2, 3]):从data[0,…]根据indices挑选第3行和第4行
- tf.gather_nd
- tf.gather_nd(data, [[[0, 0, 0], [1, 1, 1], [2, 2, 2]]])代表从每个维度上挑选特定的index,而不是一个维度将每一个最内层看做一个整体坐标来看,比如a[0,0,0], a[1,1,1]
- tf.gather_nd(data, indices=[0, 1]):从第一个维度挑选第1行,第二个维度挑选第2行
- 推荐的格式:
- [[0], [1], …]
- [[0,0], [1,1], …]
- [[0,0,0], [1,1,1], …]
- tf.boolean_mask
- tf.boolean_mask(data, mask=[True, True, False], axis=3):选择特定维度上的True对应的元素
Reshaping
详见Code
- shape, ndim
- reshape:改变张量的shape,即view
- 逆转换可能会产生bug,结果不一定就是原来的维度了,有很多可能性,如p[4, 28, 28, 3] -> [4, 784, 3] -> [4, 14, 56, 3],在处理图像数据时,要记录下转换前数据的对应content,这样才能还原数据
- expand_dims:扩展一个维度
- squeeze:将shape=1的维度删除, axis可以指定要删除的维度,前提是该维度对应的元素是1
- transpose:对张量的content进行位置调换,如[h, w] -> [w, h]
Broadcasting
详见Code
- broadcasting: 对张量的维度进行扩展的手段,指对某一个维度重复n多次,但是并没有真正的复制数据,计算时的优化
- expand
- without copying data
- tf.broadcast_to: 返回被扩展之后的数据
- tf.tile:对张量某个维度进行显式的复制n多次数据,并且会真实地在数据上体现出来
Key idea:
- Insert 1 dim ahead if needed
- Expand dims with size 1 to same size
具体如下图:
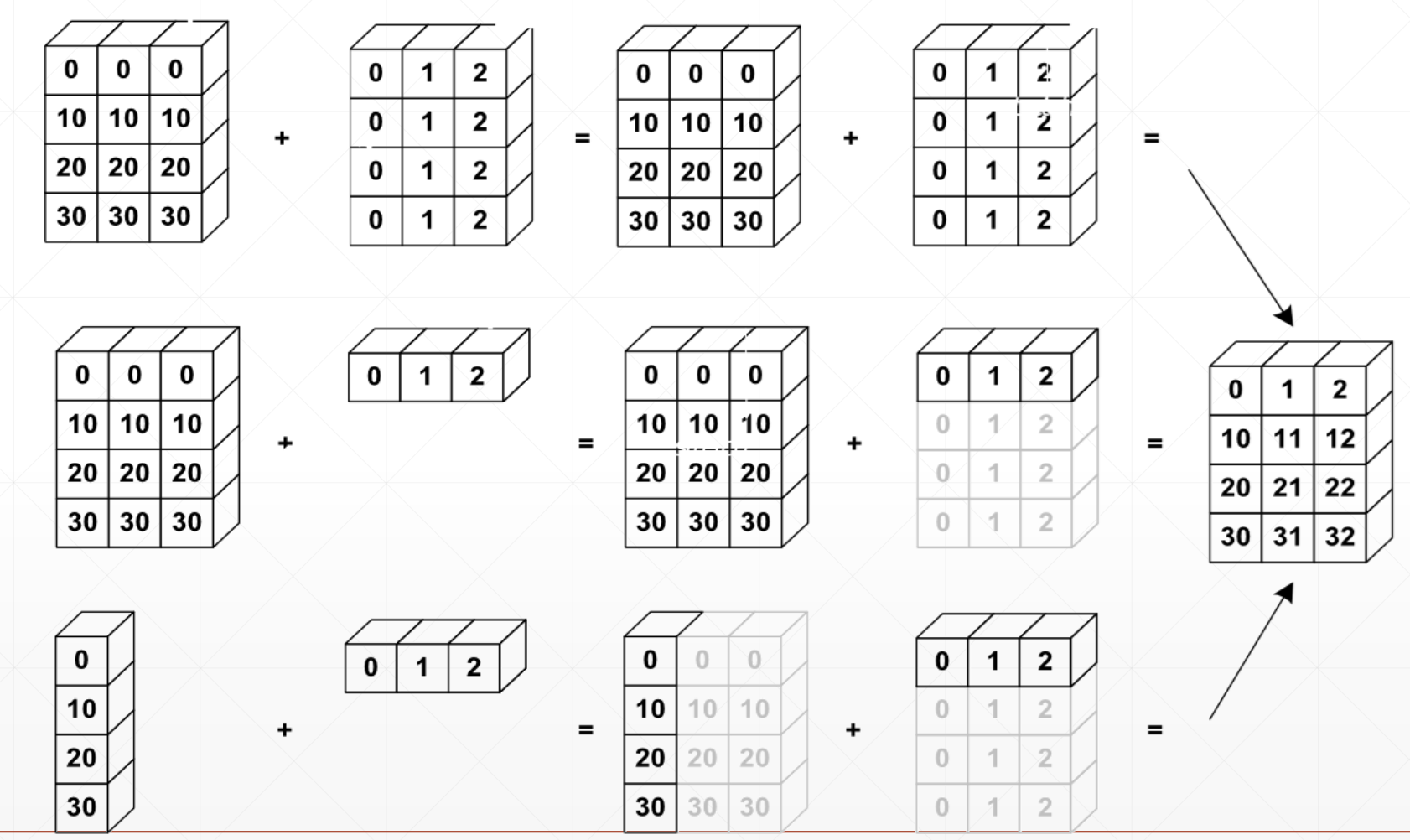
How to Understand
从左到右,大维度->小维度,首先匹配最右的小维度数据,Match from last dim.
- When it has no axis
- Create a new concept
- When it has dim of size 1
- Treat it shared by all
Why Broadcasting
- For real demanding
- Memory consumption
- 节约内存
Broadcastable
- Match from last dim
- if current_dim = 1, expand to same
- if either has no dim, insert one dim and expand to same
- otherwise, NOT broadcastable
e.g.:
- a: [4,32,14,14]
- Situation 1
- b: [1,32,1,1]
- then b -> [4,32,14,14]
- Situation 2
- b: [14, 14]
- then b -> [1,1,14,14] -> [4,32,14,14]
- Situation 3
- [2, 32, 14, 14]
- Dim 0 has dim, can NOT insert and expand to same
- Dim 0 has distinct dim, NOT size 1
- NOT broadcasting-able
Mathematical Operation
详见Code
Operation Type
- element-wise
- +-*/
- //, %
- matrix-wise
- @, matmul
- dim-wise
- reduce_mean/max/min/sum
- **, pow, square
- tf.sqrt
- tf.exp, tf.log
- linear layer: y = x@W + b
Merge and Split
详见Code
- tf.concat:拼接不同的张量,前提是除开axis定义的dim外,其他dim需要一样
- tf.split: 张量解开
- res_1 = tf.split(f, axis=3, num_or_size_splits=[2,2,4]): 可以根据num_or_size_splits进行不同的划分
- tf.stack: 创建一个新的dim,前提是两个张量的shape必须一致
- tf.unstack:张量解开
- res = tf.unstack(f, axis=3):只能按照axis均匀划分
Data Statistics
详见Code
- tf.norm
- Eukl.Norm:
- Max.norm:
- L1-norm:
- tf.reduce_min/max/mean/sum
reduce的意思是提醒会产生降维操作。- 不指定维度axis,默认是求整个张量a中的统计数据
- tf.argmax
- tf.argmin
- tf.equal
- tf.unique
Sort and TopK
详见Code - sort:直接对数据排序,返回排序后的数据 - argsort:对数据排序,但是返回的是原始数据的index,通过gather可以获得排序后的数据 - TopK - Top-5 ACC.
Accuracy:
def accuracy(output, target, top_k=(1,)):
max_k = max(top_k)
batch_size = target.shape[0]
pred = tf.math.top_k(output, k=max_k).indices
pred = tf.transpose(pred, perm=[1, 0])
target_ = tf.broadcast_to(target, pred.shape)
correct = tf.equal(pred, target_) # [k,b]
result = []
for k in top_k:
correct_k = tf.cast(tf.reshape(correct[:k], [-1]), dtype=tf.float32)
correct_k = tf.reduce_sum(correct_k)
acc = float(correct_k * (100.0 / batch_size))
result.append(acc)
return result
Padding and Copying
详见Code
- pad:在原始数据的周围填充
- tf.tile(aa, [2, 1, 1]):复制原始数据,但是ndim维度必须一直
- broadcast_to:维度不一致会自动broadcast,需要满足broadcast的条件
Padding:
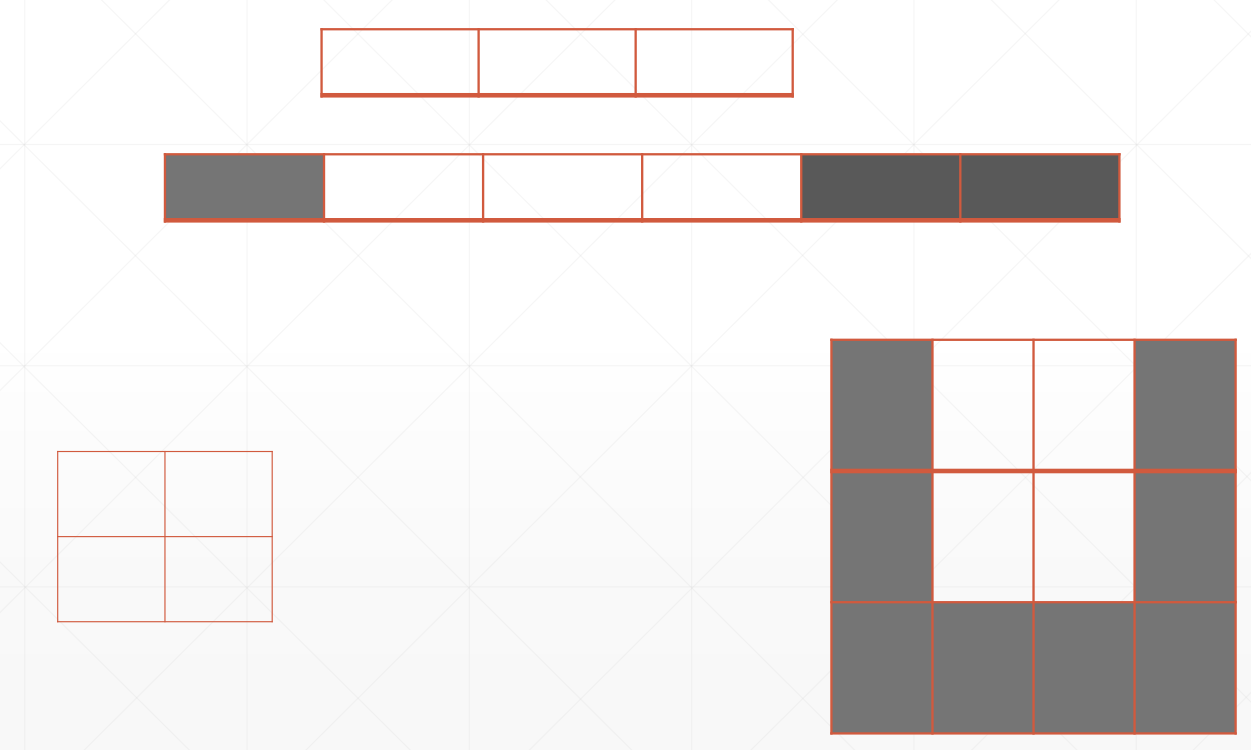
Clipping
详见Code
- clip_by_value
- relu
- clip_by_norm
- gradient clipping
- Gradient Exploding or vanishing
- 等比例放缩梯度矩阵模的大小,而不改变梯度方向,这保证了梯度矩阵的范数最大值在一定范围
- new_grads, total_norm = tf.clip_by_global_norm(grads, 15)
High-level Operation
详见Code
Where
tf.where(mask)用来查找满足特定条件的index,where的參數需要是bool类型的tensor:
# where
a = tf.random.normal([3, 3])
mask = a > 0
a_1 = tf.boolean_mask(a, mask)
indices = tf.where(mask)
a_2 = tf.gather_nd(a, indices)
tf.where(cond, A, B) 如果cond为True,选择A对应的元素,反之选择B对应的元素
A = tf.ones([3, 3]) # where(cond, A, B) 如果cond为True,选择A对应的元素,反之选择B对应的元素
B = tf.zeros([3, 3])
C = tf.where(mask, A, B)
print(C)
Scatter_nd
tf.scatter_nd,底板数据是全零的,将indices对应位置的数据进行用updates对应的数据替换
indices = tf.constant([[4], [3], [1], [7]])
updates = tf.constant([9, 10, 11, 12])
shape = tf.constant([8])
d = tf.scatter_nd(indices, updates, shape)
print(d)
Meshgrid
使用meshgrid方法可以很方便地生成一个坐标轴点的坐标。详见Code
Loading Dataset
Keras.datasets: - boston housing - mnist/fashion mnist - cifar10/100 - imdb
Functions:
- tf.shuffle: 将数据集随机打散
- tf.map: 将数据逐个进行map操作
- tf.batch: 设置数据的一个batch
- tf.repeat(n): 将整个数据集复制n次,默认参数是永远不会退出
Test/Evaluation
- train/evaluation/test splitting
- Stop at the best epoch
- Use the best epoch model to production
Reference
Note: Cover Picture