Generative Adversarial Network
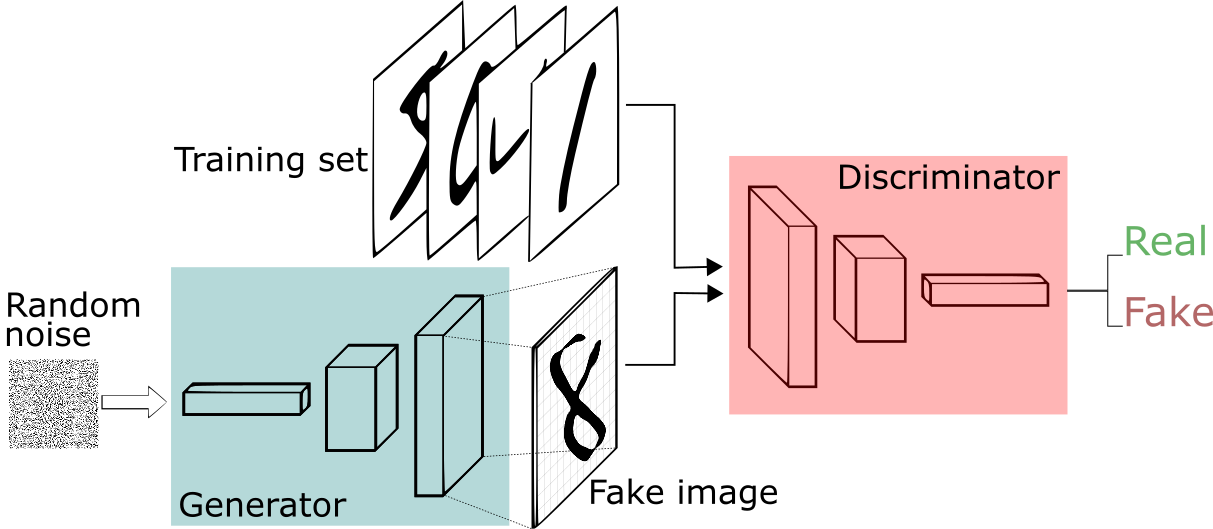

How to Train
Intuition
DCGAN
详见Code

Transposed Convolution
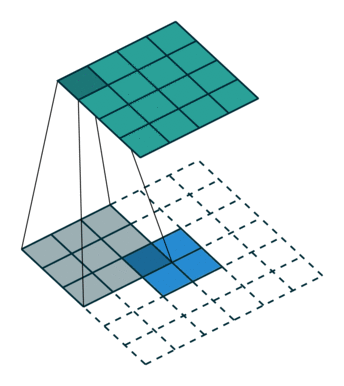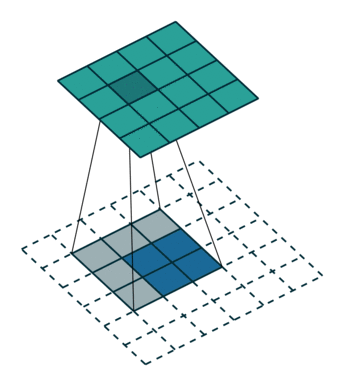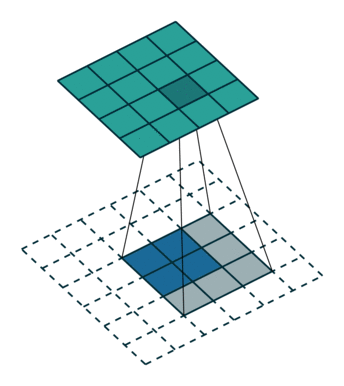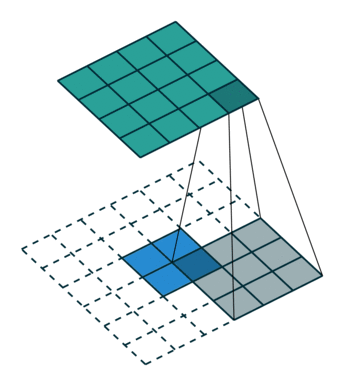
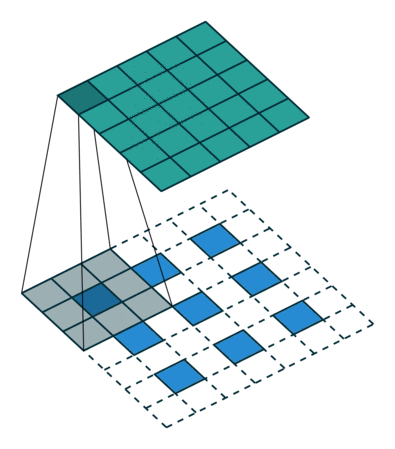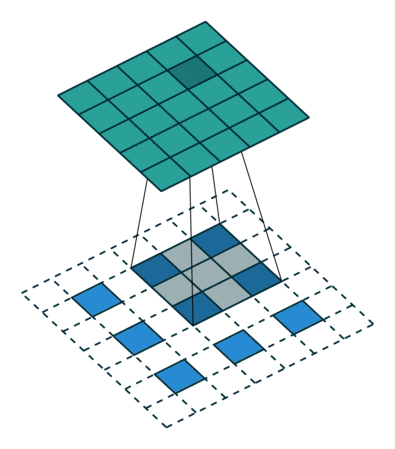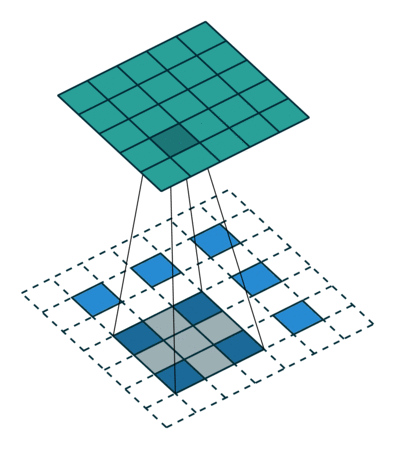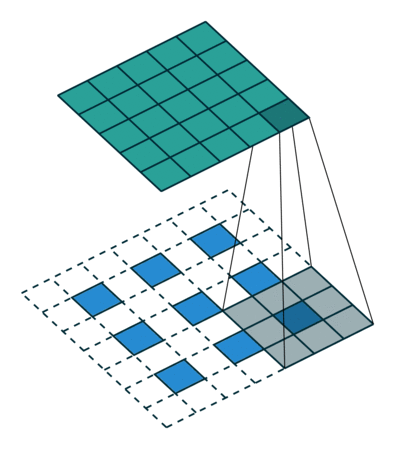
def celoss_ones(logits):
# [b, 1]
# [b] = [1, 1, 1, 1,]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits,
labels=tf.ones_like(logits))
return tf.reduce_mean(loss)
def celoss_zeros(logits):
# [b, 1]
# [b] = [1, 1, 1, 1,]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits,
labels=tf.zeros_like(logits))
return tf.reduce_mean(loss)
def d_loss_fn(generator, discriminator, batch_z, batch_x, is_training):
# 1. treat real image as real
# 2. treat generated image as fake
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
d_real_logits = discriminator(batch_x, is_training)
d_loss_real = celoss_ones(d_real_logits) # 正样本判断为真
d_loss_fake = celoss_zeros(d_fake_logits) # 负样本判断为假
loss = d_loss_fake + d_loss_real # 判别器的目标是将真的判断为真,假的判断为假
return loss
def g_loss_fn(generator, discriminator, batch_z, is_training):
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
loss = celoss_ones(d_fake_logits) # 这个地方的目标是欺骗生成器,使得生成的图片是真的,因此label为1
return loss
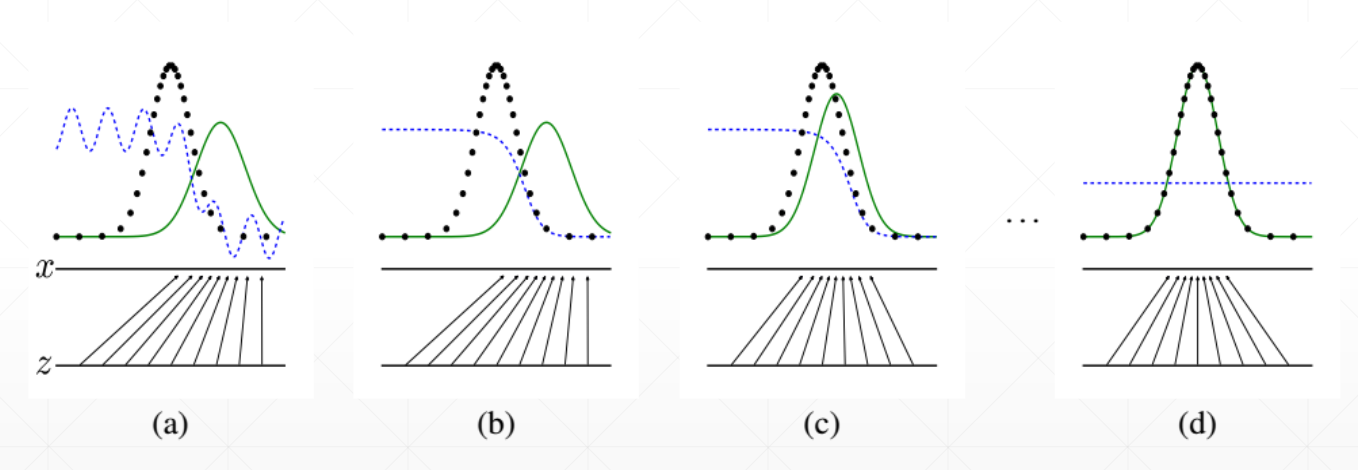
Training Stability
使用KL散度作为损失评价会造成GAN训练的不稳定。因为当两个分布完全没有重叠的时候,KL or JS的结果始终为log2,梯度也会出现消失的现象,导致GAN训练不稳定。

Gradient Vanishing
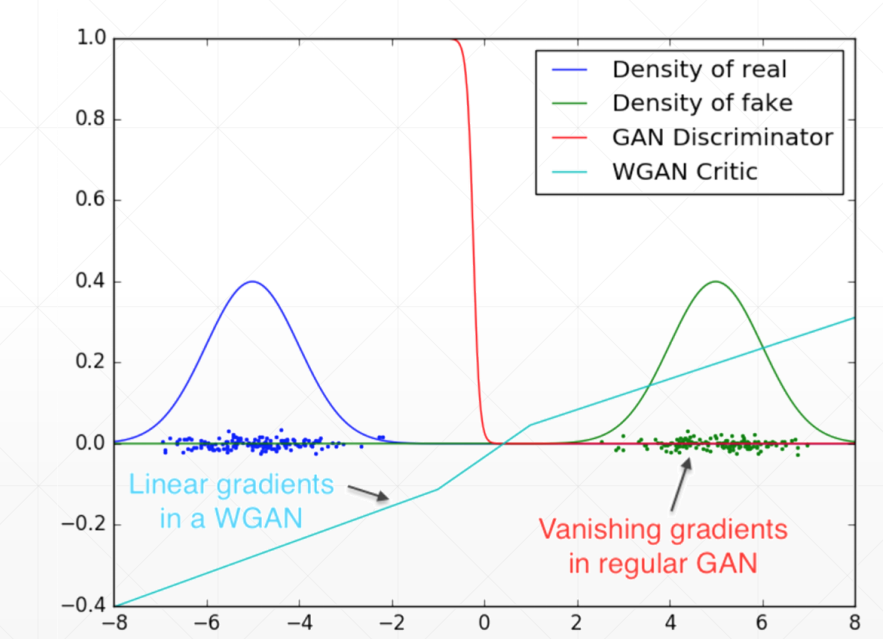
WGAN
详见Code
Wasserstein Distance: 推土机距离
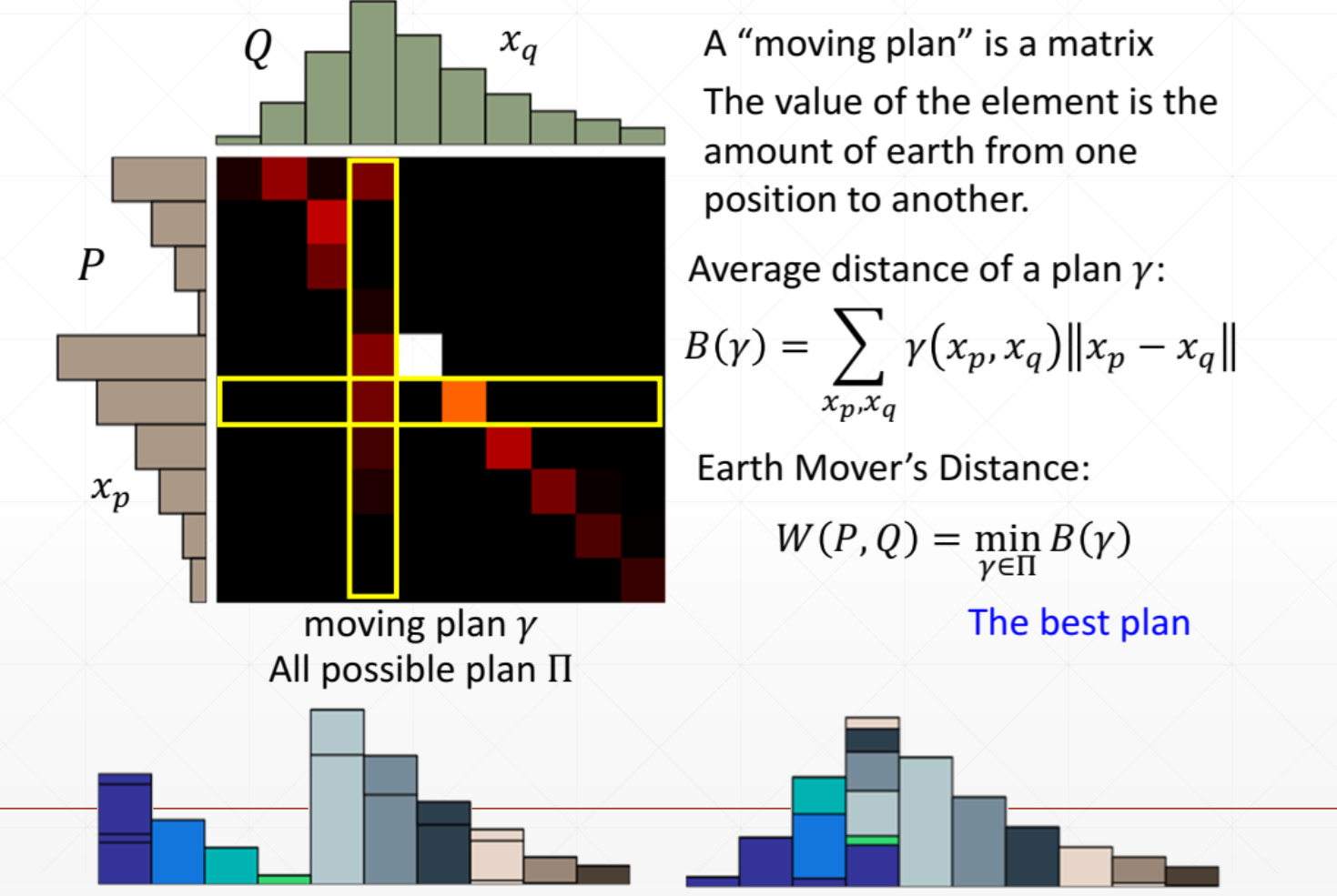
Wasserstein距离可以很好地解决两个分布没有Overlap的情况。

WGAN-Gradient Penalty
WGAN-GP从理论上证明了,只要神经网络函数满足L-Lipschitz的约束,则一定会收敛。
注意是针对x做L1-Lipschitz的约束,即其倒数要小于1,是图片,而不是weight参数。
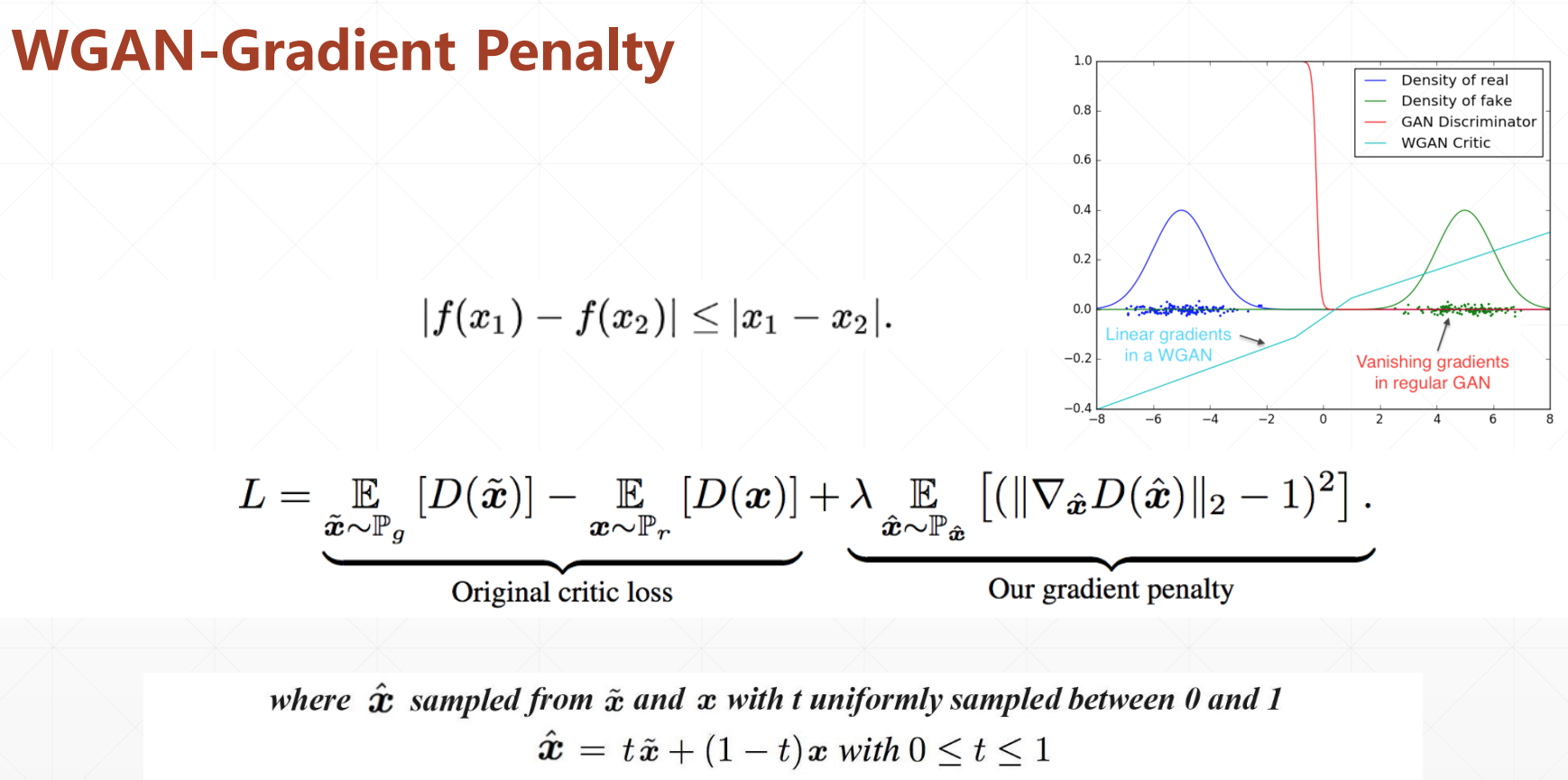
WGAN和GAN的不同之处在于损失函数不一样了:
def gradient_penalty(discriminator, batch_x, fake_image):
batch_size = batch_x.shape[0]
# [b, h, w, c]
t = tf.random.uniform([batch_size, 1, 1, 1])
# [b, 1, 1, 1] => [b, h, w, c]
t = tf.broadcast_to(t, batch_x.shape)
interpolate = t * batch_x + (1 - t) * fake_image
with tf.GradientTape() as tape:
tape.watch([interpolate])
d_interpolate_logits = discriminator(interpolate, training=True)
grads = tape.gradient(d_interpolate_logits, interpolate)
# grads:[b, h, w, c] => [b, -1]
grads = tf.reshape(grads, [grads.shape[0], -1])
gp = tf.norm(grads, axis=1) # [b]
gp = tf.reduce_mean((gp - 1) ** 2)
return gp
def d_loss_fn(generator, discriminator, batch_z, batch_x, is_training):
# 1. treat real image as real
# 2. treat generated image as fake
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
d_real_logits = discriminator(batch_x, is_training)
d_loss_real = celoss_ones(d_real_logits) # 正样本判断为真
d_loss_fake = celoss_zeros(d_fake_logits) # 负样本判断为假
gp = gradient_penalty(discriminator, batch_x, fake_image)
loss = d_loss_fake + d_loss_real + 10. * gp # 判别器的目标是将真的判断为真,假的判断为假,WGAN多了Gradient Penalty
return loss, gp
Reference
Note: Cover Picture