Temporal Signals
带有时间信息的信号,序列编码很重要。
通常Sequence Embedding的张量格式为:[b, seq_len, feature_len],代表有b个句子,每个句子有seq_len个单词(隐含了有seq_len个时间戳),每个单词有feature_len个数表示。
相对来说,按照时间戳来对数据进行处理更方便理解,如:
Word Embedding
How to represent a word: [words, word_vec]
- One-hot encoding
- Sparse
- High-dim
We need semantic Similarity and trainable. Common word embedding methods:
- Word2Vec vs Glove
Tensorflow中的Embedding Layer:
import tensorflow as tf
x = tf.range(5)
x = tf.random.shuffle(x)
print(x)
net = layers.Embedding(10, 4) # 10代表整个语料库有10个单词,4代表将每个单词映射到4维的向量表示
print(net(x))
print(net.trainable)
print(net.trainable_variables)
Sentiment Analysis
可以对每个单词进行一个单独的embedding,然后对结果进行分类判断,但是弊端是句子长的情况下,参数太多,最重要的是没有包含上下文信息,仅仅是单独的单词信息。
Weight Sharing
针对每一个单词,共享同一套Embedding网络的参数,不管句子的长度,参数都固定。在不同的单词之间传递网络内部信息,即保存中间信息。
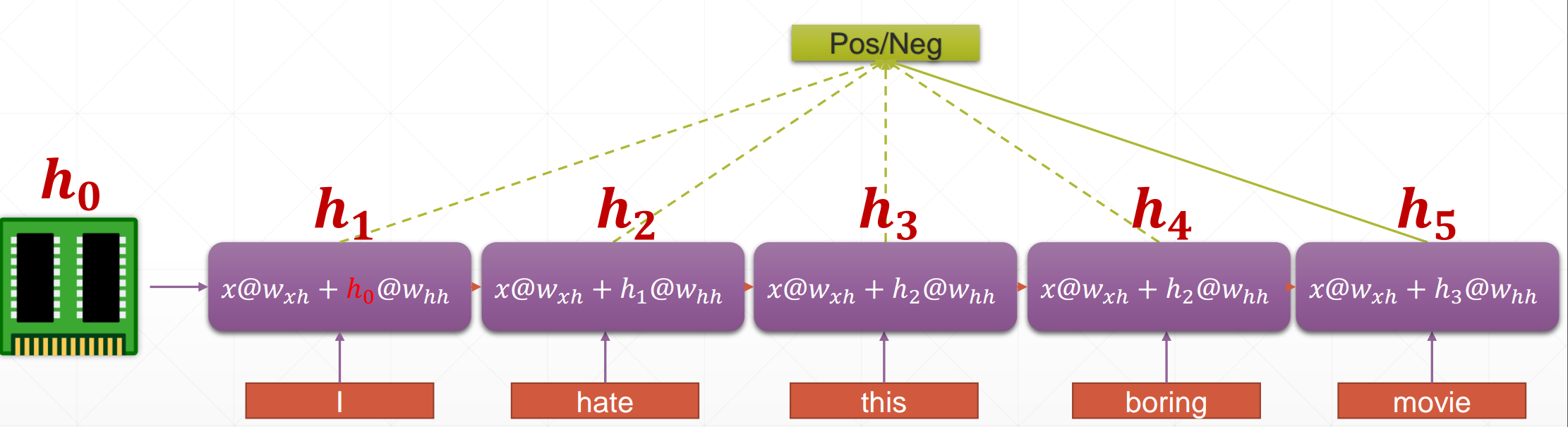
可以将每个单词对应的输出结合起来进行后面的分类网络输入,也可以只使用最后一个单词的输出作为后面网络的输入,因为可以认为其已经包含了整个句子的有效信息,其最全面,最丰富。
Formulation
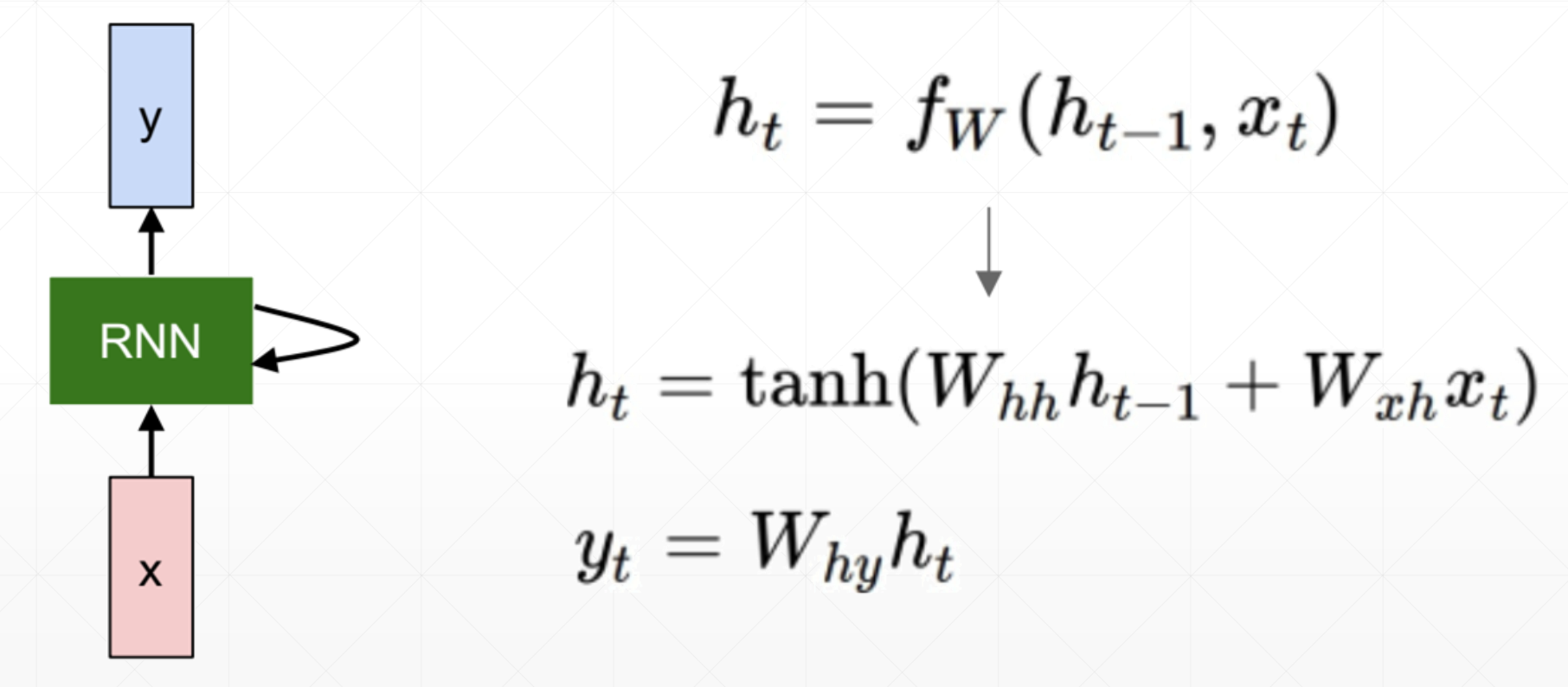
How to Train
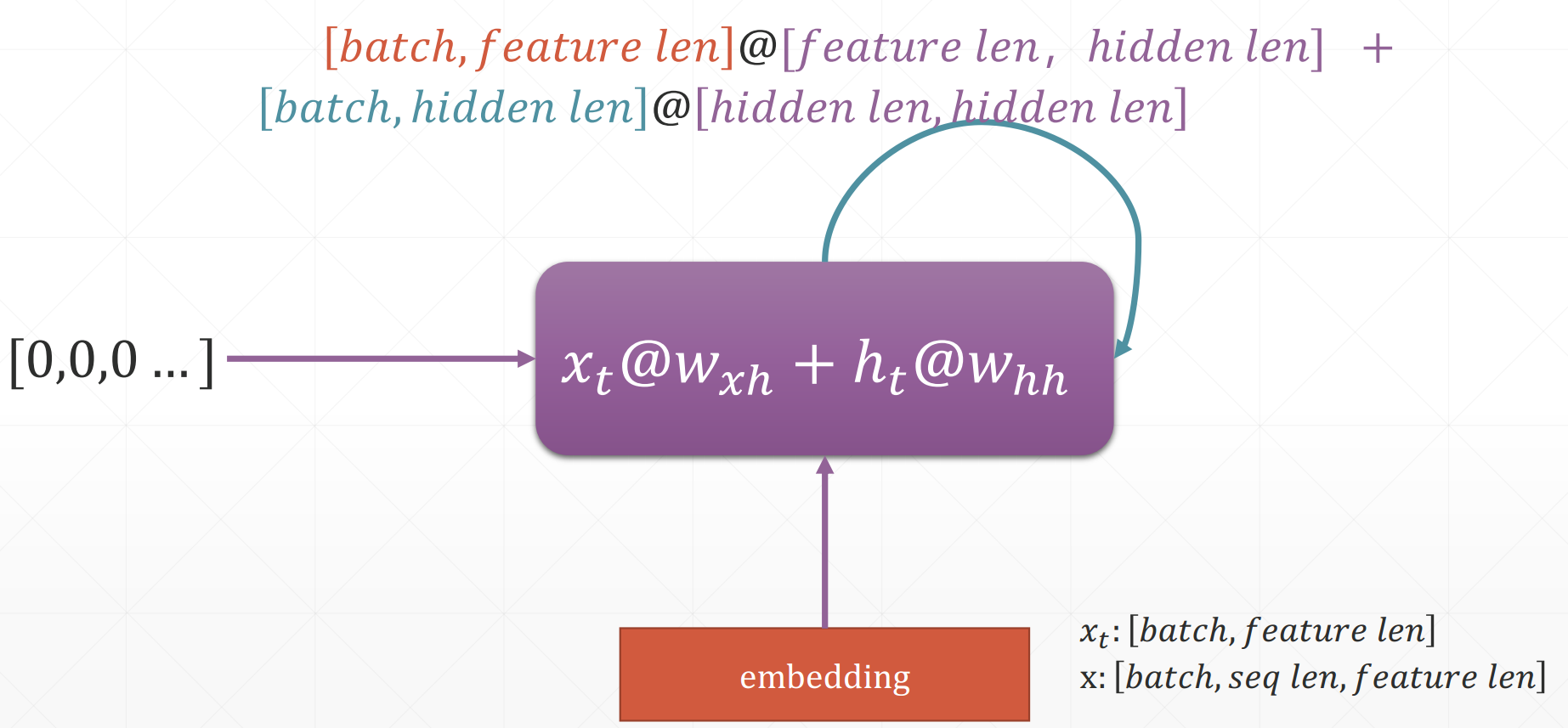
RNN
详见Code
- out, h1 = call(x, h0)
- x: [b, seq_len, word_vec]
- h0/h1: [b,h dim]
- out: [b, h dim]
在Tensorflow中有两种实现方式:
- SimpleRNNCell
- Single layer
- Multi layers
- RNNCell
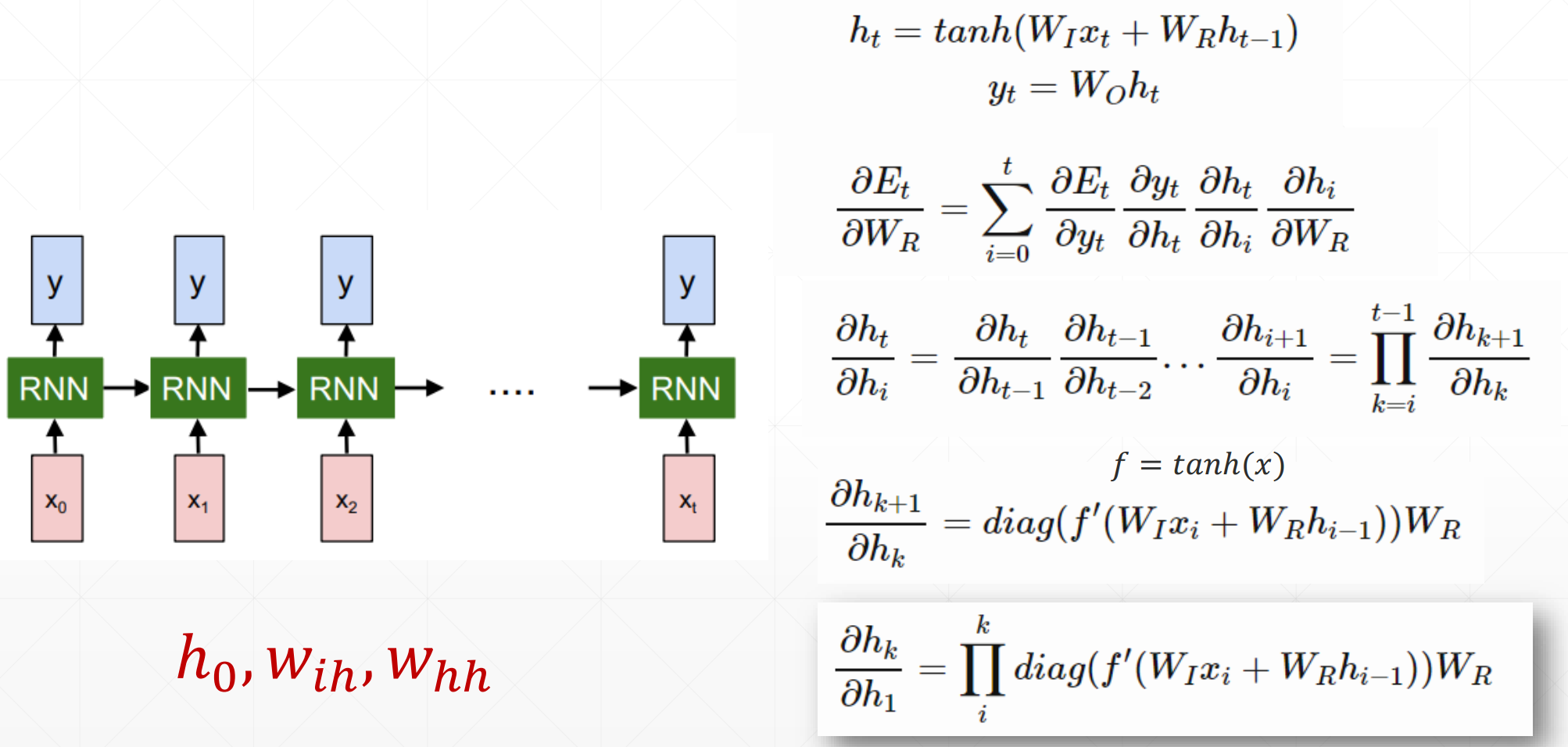
Gradient Vanishing and Gradient Exploding
The most motivational poster ever:
$$ 1.01^{365} = 37.8 $$
$$ 0.99^{365} = 0.03 $$
with tf.GradientTape() as tape:
logits = model(x)
loss = criteon(y, logits)
grads = tape.gradient(loss, model.trainable_variables)
# Must clip gradient here or it will dis-converge!
grads = [tf.clip_by_norm(g, 15) for g in grads] # 将梯度裁剪到一个范围
optimizer.apply_gradients(zip(grads, model.trainable_variables))
Gradient Exploding
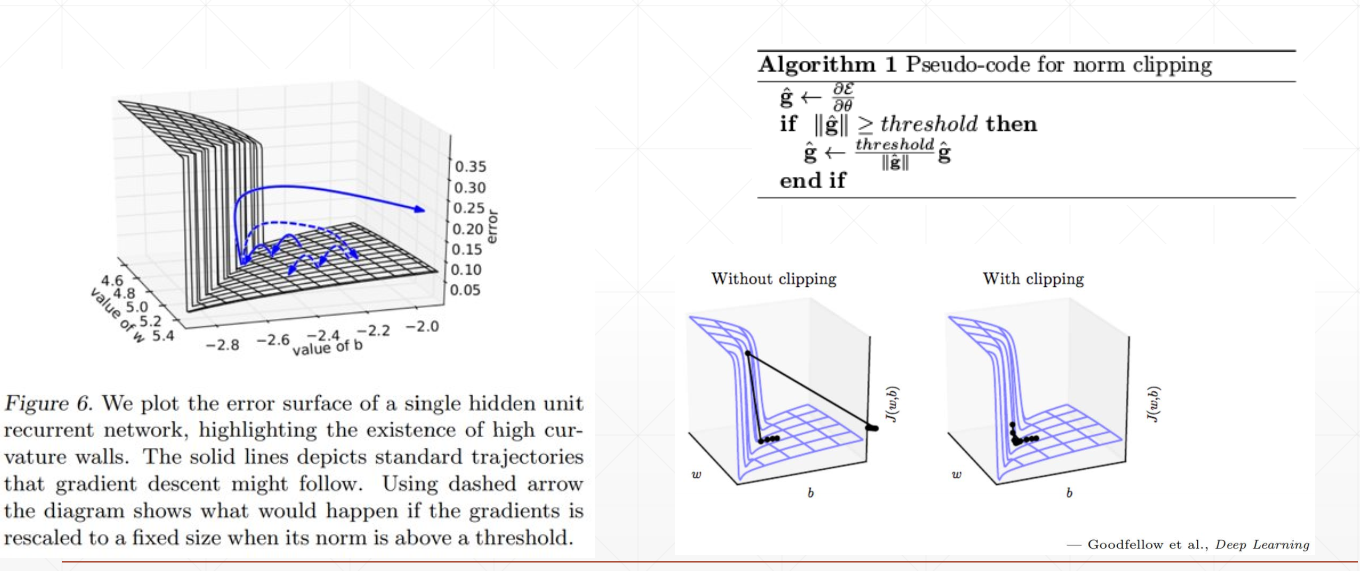
See On the difficulty of training recurrent neural networks
Gradient Vanishing
LSTM
Intuitive pipeline:
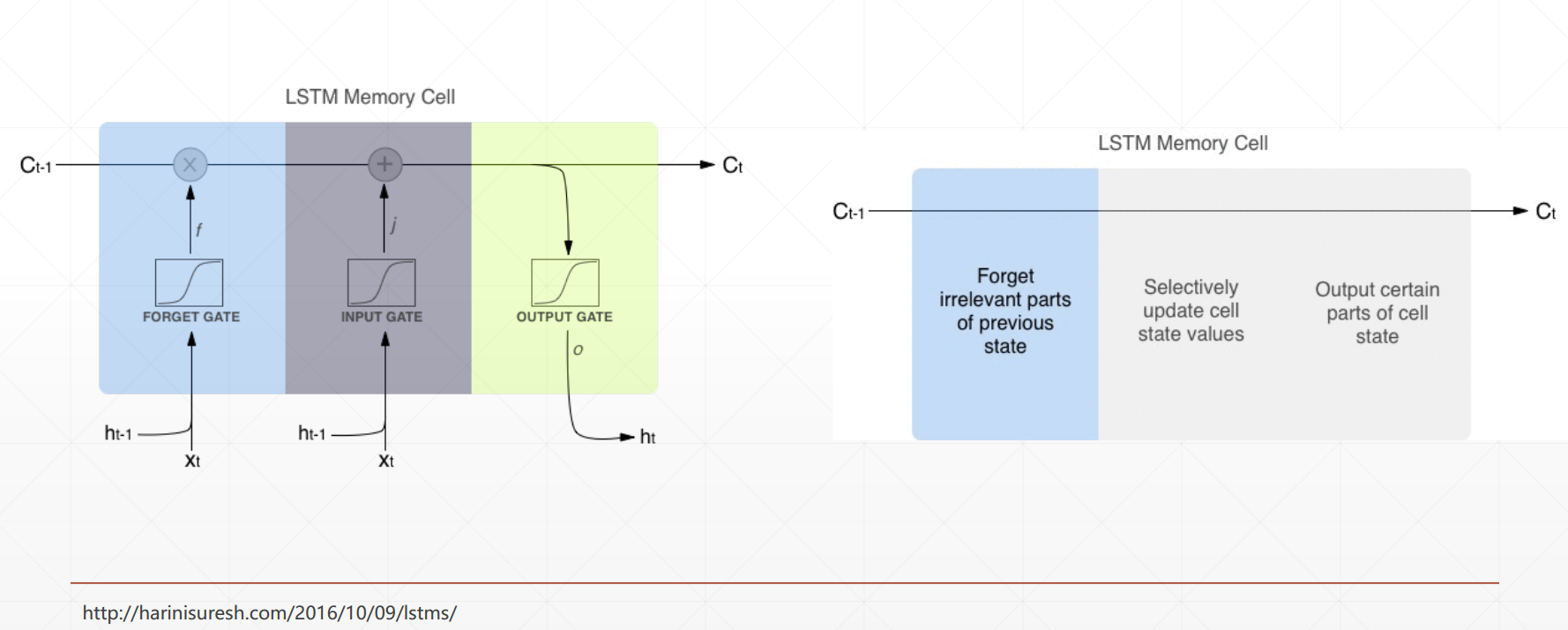
See The Vanishing Gradient Problem
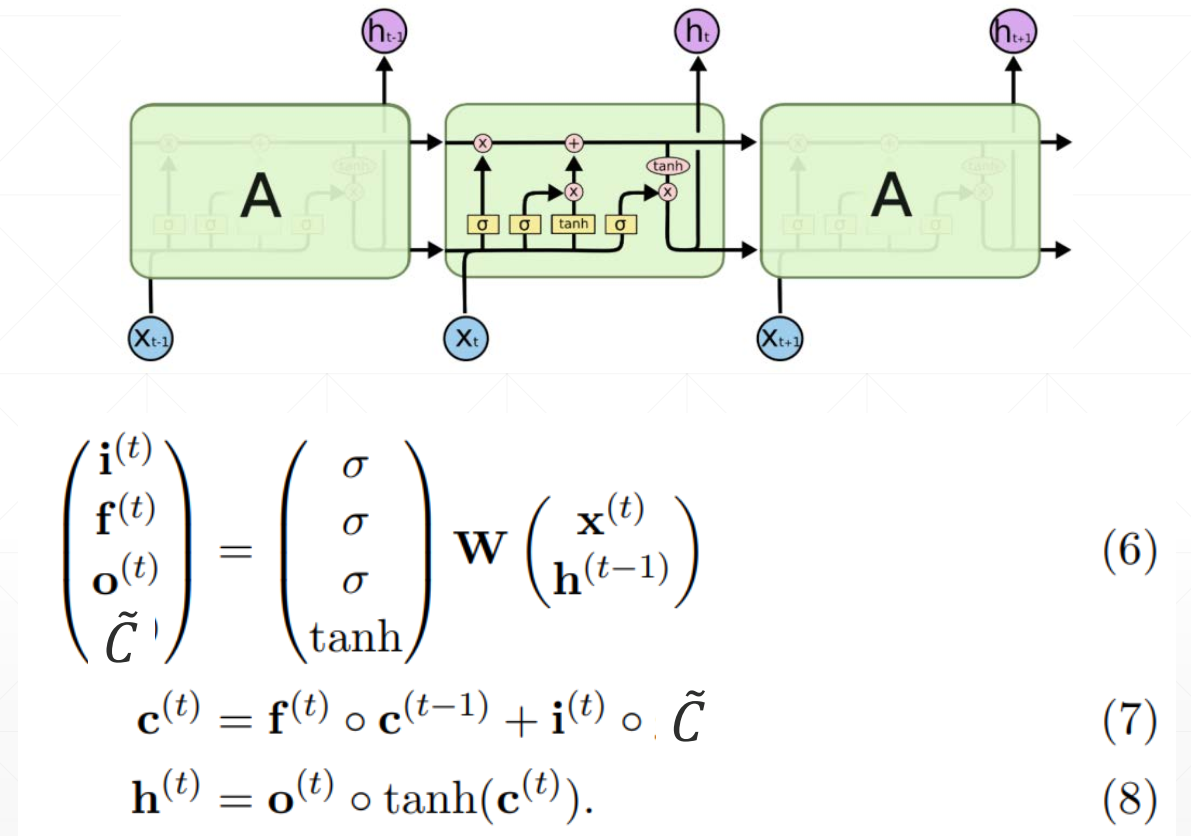
See Exploding and Vanishing Gradients
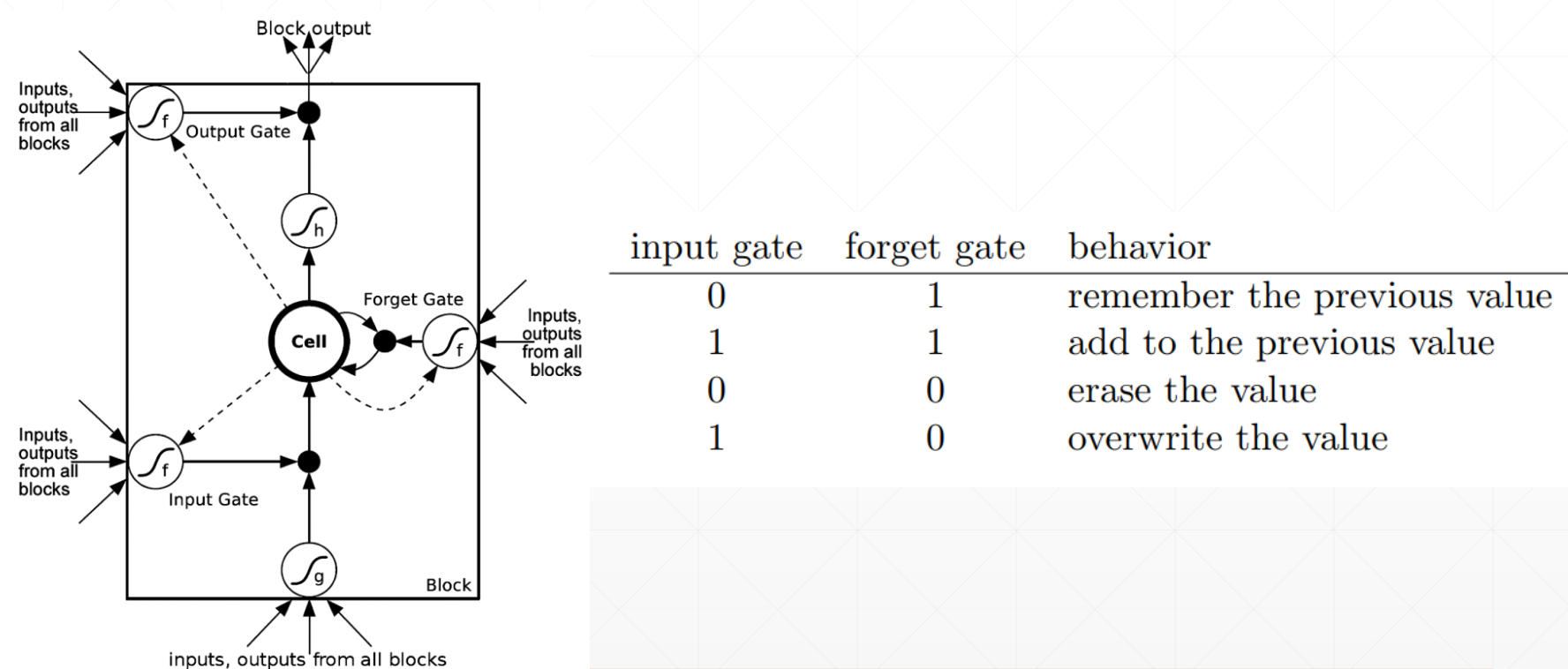
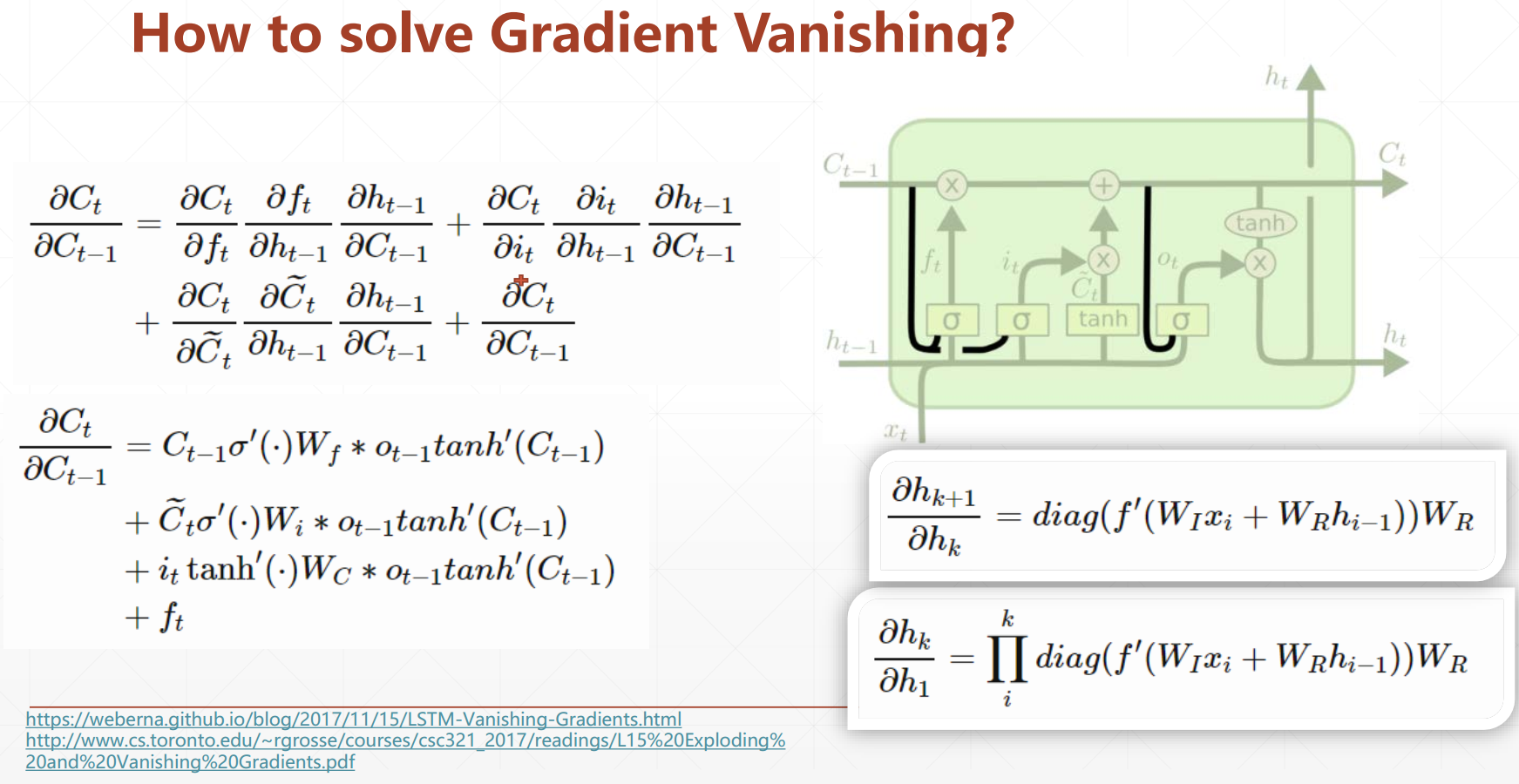
How to Solve Gradient Vanishing
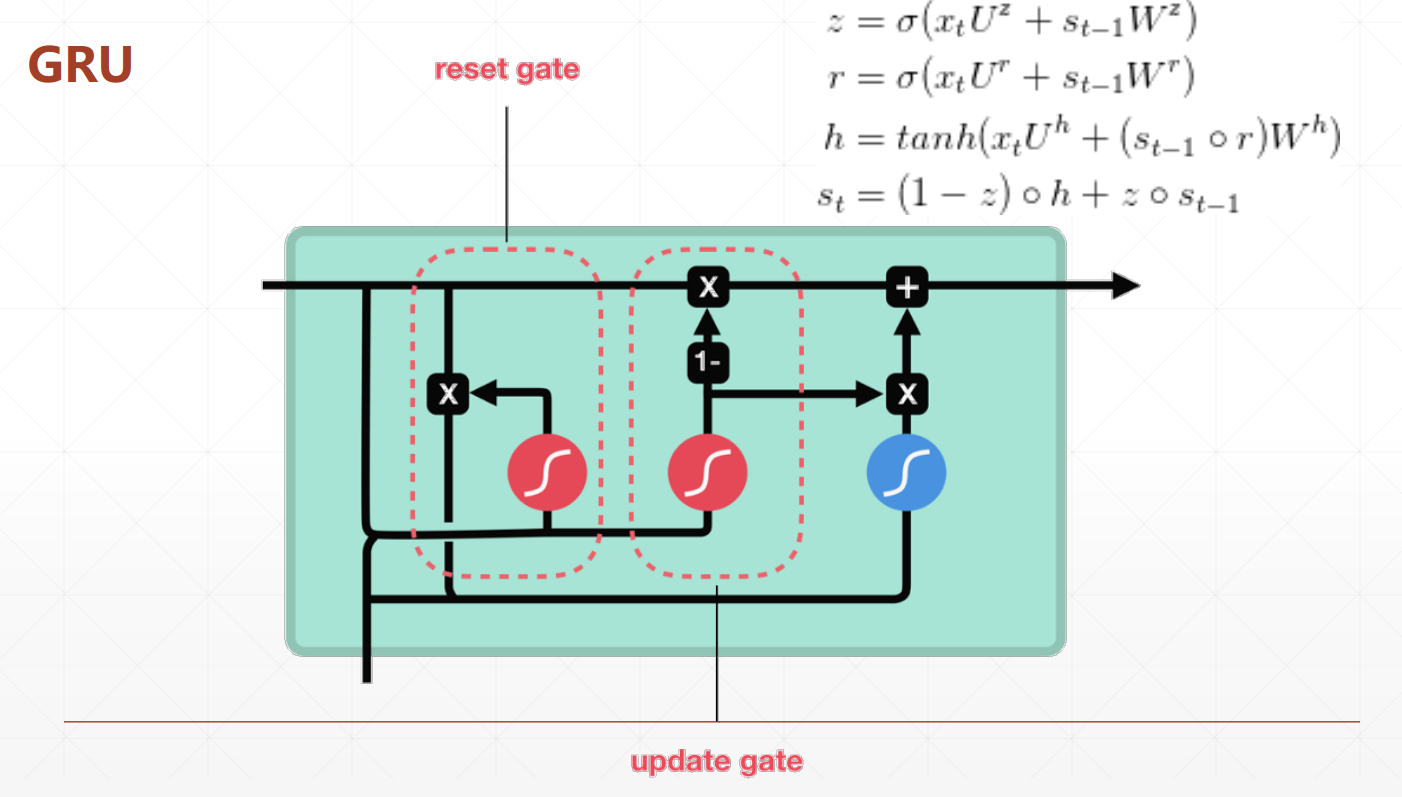
GRU
- Simpler
- Lower computation cost
Reference
Note: Cover Picture